Introdução
Uma série temporal é uma série de pontos de dados indexados (ou listados/representados graficamente) na ordem do tempo. Mais comumente, uma série temporal é uma sequência tomada em sucessivos pontos igualmente espaçados no tempo.
As séries temporais são frequentemente plotadas através de gráficos de linhas. Elas são usadas em campos como:
- Estatísticas
- Processamento de Sinais
- Reconhecimento de Padrões
- Econometria
- Finanças Matemáticas
- Previsão do Tempo
- Previsão de Terremotos
- Eletroencefalografia
- Engenharia de Controle
- Engenharia de Comunicações
- Astronomia
Em grande parte em qualquer domínio da ciência e engenharia aplicada que envolva medições temporais.
Exemplos de séries temporais incluem:
- O monitoramento contínuo da freqüência cardíaca de uma pessoa
- Leituras de hora em hora da temperatura do ar
- Preço de fechamento diário das ações de uma empresa
- Dados mensais de precipitação e números de vendas anuais
A análise de séries temporais é geralmente usada quando há 50 ou mais pontos de dados em uma série. Se a série temporal exibir sazonalidade, deve haver 4 a 5 ciclos de observações para ajustar um modelo sazonal aos dados.
Objetivos
Os principais objetivos da análise de séries temporais são respectivamente:
- Descritiva: Identificar padrões em dados correlacionados - tendências e variação sazonal
- Explicação: Compreender e modelar os dados
- Previsão: Previsão de tendências de curto prazo a partir de padrões anteriores
- Análise de intervenção: Como um único evento altera a série temporal?
- Controle de Qualidade: Desvios de um tamanho especificado indicam um problema
As séries temporais são analisadas de forma a entendermos a estrutura e função que produzem as observações. A compreensão dos mecanismos de uma série temporal permite desenvolver um modelo matemático que explica os dados de maneira que a previsão, o monitoramento ou o controle possam ocorrer.
Exemplos incluem previsão/estimativa, amplamente usada em economia e negócios. O monitoramento das condições ambientais, de um input ou de um output, que é comum na ciência e na indústria. O controle de qualidade é usado em ciência da computação, comunicações e indústria.
Padrões
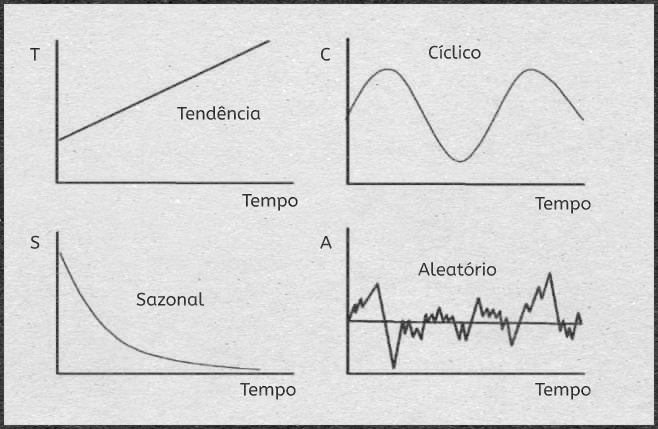
Supõe-se que um conjunto de dados de séries temporais possua pelo menos um padrão sistemático. Os padrões mais comuns são tendências e sazonalidade.
- As tendências são geralmente lineares ou quadráticas. Para encontrar tendências, médias móveis ou análise de regressão são frequentemente usadas.
- A sazonalidade é uma tendência que se repete sistematicamente ao longo do tempo.
Uma segunda suposição é que os dados exibem um processo aleatório suficiente para que seja difícil identificar os padrões sistemáticos dentro dos dados. As técnicas de análise de séries temporais costumam empregar algum tipo de filtro nos dados para atenuar o erro. Outros padrões potenciais têm a ver com efeitos persistentes de observações anteriores ou erros aleatórios anteriores.
Complexidade
As observações feitas ao longo do tempo podem ser discretas ou contínuas. Ambos os tipos de observações podem ser igualmente espaçados, desigualmente espaçados ou ter dados ausentes. As medições discretas podem ser registradas a qualquer intervalo de tempo, mas geralmente são realizadas em intervalos igualmente espaçados. As medições contínuas podem ser espaçadas aleatoriamente no tempo, como por exemplo: medir terremotos à medida que ocorrem pois um instrumento está gravando constantemente ou pode envolver a medição constante de um fenômeno natural como a temperatura do ar ou de um processo como a velocidade de um avião.
As séries temporais são muito complexas porque cada observação depende de alguma forma da observação anterior e geralmente é influenciada por mais de uma observação anterior. O erro aleatório também é influente de uma observação para outra. Essas influências são chamadas de autocorrelação - relações dependentes entre observações sucessivas da mesma variável. O desafio da análise de séries temporais é extrair os elementos de autocorrelação dos dados, para entender a própria tendência ou modelar os mecanismos subjacentes.
As séries temporais refletem a natureza estocástica da maioria das medições ao longo do tempo. Assim, os dados podem ser distorcidos, com média e variação não constantes, não normalmente distribuídas e não amostradas ou independentes aleatoriamente. Outro aspecto não normal das observações de séries temporais é que elas geralmente não são espaçadas uniformemente no tempo devido à falha do instrumento ou simplesmente devido à variação no número de dias em um mês.
Variações dos Dados das Séries Temporais
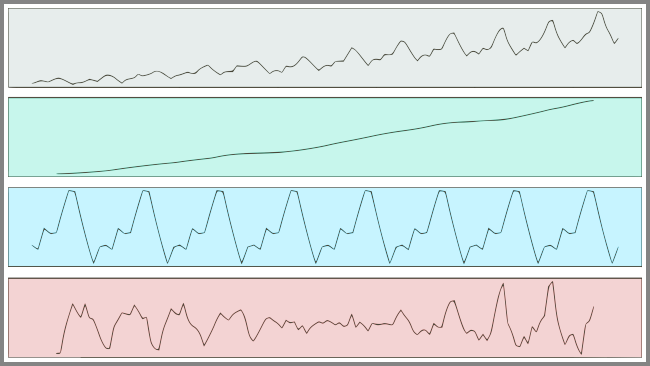
As formas de variações mais comuns que encontramos nas Séries Temporais são respectivamente:
- Variação de Tendência: Os dados movem-se para cima ou para baixo em um padrão razoavelmente previsível por um longo período de tempo.
- Variação Sazonal: Regular e Periódico, repete-se durante um período específico, como dia, semana, mês, estação etc.
- Variação Cíclica: A palavra “ciclo” refere-se à afluência e depressão do período, altos e baixos, “booms e slums” de uma série temporal, mais comumente vistos em ciclos de negócios. Esses ciclos não são estritamente periódicos, como o da variação sazonal, mas geralmente ocorrem em um período de 3 a 12 anos, dependendo da natureza da série temporal.
- Variação Aleatória: Irregular ou Residual, não se enquadra em nenhuma das três classificações acima.
O gráfico a seguir ilustra a ideia das variações de dados de Séries Temporais
Métodos para Análises
Os métodos para análise de séries temporais podem ser divididos em duas classes:
- Métodos no domínio da frequência: que incluem por exemplo análise espectral e análise de wavelets.
- Métodos no domínio do tempo: que incluem por exemplo análise de autocorrelação a e correlação cruzada.
No domínio do tempo, a correlação e a análise podem ser feitas de maneira semelhante a um filtro, usando correlação em escala, mitigando a necessidade de operar no domínio da frequência.
Além disso, as técnicas de análise de séries temporais podem ser divididas em métodos:
Uma vez que construímos uma base teórica a respeito das Séries Temporais, vamos agora começar nossa análise com o auxílio da biblioteca Pandas.
Análise de Séries Temporais
Caso possua alguma dúvida em relação ao código apresentado, o Jupyter-Notebook deste tutorial pode ser encontrado em: Séries Temporais
Instalando Pandas
Nossa primeira tarefa é instalar Pandas, assumindo que já temos a linguagem Python instalada em nossa máquina vamos então digitar o comando
pip install pandasPara verificar se a instalação ocorreu com sucesso, você pode executar o comando: python -c 'import pandas; print(pandas.__version__);', estou trabalhando com a versão 1.0.3 nesse guia.
Dados sobre Bitcoin
Precisamos agora obter os dados sobre a criptomoeda Bitcoin, para isso, o website CoinMarketCap pode nos ajudar. Através dele, coletei dados sobre os preços do Bitcoin entre os meses de Janeiro até Abril do ano de 2020.
Para obter o arquivo CSV que vamos trabalhar, visite o endereço: bitcoin.csv
Com os dados em mãos, podemos agora efetivamente iniciar nossa análise.
Carregando os Dados em um DataFrame
DataFrame é uma estrutura de dados rotulada bidimensional com colunas de tipos potencialmente diferentes. Você pode pensar nele como uma planilha ou tabela SQL. Geralmente é o objeto de pandas mais usado, capaz de nos oferecer poderosos métodos para manipularmos nossos dados.
Começaremos então importando as bibliotecas que vamos trabalhar
import pandas as pd
from datetime import datetimeObserve que além do Pandas, também estou importando a biblioteca datetime, que também pode nos auxiliar com as Séries Temporais, finalmente podemos então carregar os dados
URL = 'http://arquivos.netlify.com/timeseries/btc.csv'
dados = pd.read_csv(URL, index_col=0)Através do método read_csv() fomos capazes de carregar o arquivo CSV em um DataFrame Pandas, agora temos a habilidade de executar operações nele e invocar métodos poderosos.
Explorando os Dados
Ao trabalharmos com Pandas, é muito comum iniciarmos a exploração dos dados com o método head(). Utilizado para obtermos as n primeiras linhas de nosso DataFrame, muito importante para testarmos rapidamente se nosso objeto possui o tipo certo de dados.
dados.head()Obteremos como output as cinco primeiras linhas de nosso DataFrame
| Date | Open | High | Low | Close | Volume | Market Cap | |
|---|---|---|---|---|---|---|---|
| 0 | Apr 28, 2020 | 7796.97 | 7814.53 | 7730.81 | 7807.06 | 33187959921 | 143266252261 |
| 1 | Apr 27, 2020 | 7679.42 | 7795.6 | 7679.42 | 7795.6 | 36162144725 | 143040988590 |
| 2 | Apr 26, 2020 | 7570.14 | 7700.59 | 7561.41 | 7679.87 | 33070154491 | 140903867573 |
| 3 | Apr 25, 2020 | 7550.48 | 7641.36 | 7521.67 | 7569.94 | 32941541447 | 138874072264 |
| 4 | Apr 24, 2020 | 7434.18 | 7574.2 | 7434.18 | 7550.9 | 34636526286 | 138512029491 |
O atributo shape nos retorna uma tupla com o número de linhas e colunas de nosso DataFrame
dados.shapeNos é retornado (119, 7), respectivamente 119 linhas e 7 colunas.
Um problema que podemos detectar em nosso DataFrame é a coluna Date, que atualmente é uma string, podemos confirmar com o seguinte comando
type(dados.loc[0]['Date'])Nos será retornado str, o que não é interessante para nós, queremos trabalhar com um objeto Timestamp de forma que consigamos manipular a data de forma eficiente, para a nossa sorte, Pandas implementa um método to_datetime que é capaz de converter um argumento para datetime.
dados['Date'] = pd.to_datetime(dados['Date'])
type(dados.loc[0]['Date'])Feita a conversão, agora a coluna Date possui um objeto do tipo pandas._libs.tslibs.timestamps.Timestamp. Novamente vamos executar o método head() para visualizarmos a mudança em nosso dados.
dados.head()Nos retornará
| Date | Open | High | Low | Close | Volume | Market Cap | |
|---|---|---|---|---|---|---|---|
| 0 | 2020-04-28 00:00:00 | 7796.97 | 7814.53 | 7730.81 | 7807.06 | 33187959921 | 143266252261 |
| 1 | 2020-04-27 00:00:00 | 7679.42 | 7795.6 | 7679.42 | 7795.6 | 36162144725 | 143040988590 |
| 2 | 2020-04-26 00:00:00 | 7570.14 | 7700.59 | 7561.41 | 7679.87 | 33070154491 | 140903867573 |
| 3 | 2020-04-25 00:00:00 | 7550.48 | 7641.36 | 7521.67 | 7569.94 | 32941541447 | 138874072264 |
| 4 | 2020-04-24 00:00:00 | 7434.18 | 7574.2 | 7434.18 | 7550.9 | 34636526286 | 138512029491 |
Perceba que a coluna Date teve seu formato alterado. Executaremos agora o método info() que nos trará um sumário conciso de nosso DataFrame.
dados.info()Onde teremos como output detalhes sobre nosso DataFrame
<class 'pandas.core.frame.DataFrame'>
Int64Index: 119 entries, 0 to 118
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Date 119 non-null datetime64[ns]
1 Open 119 non-null float64
2 High 119 non-null float64
3 Low 119 non-null float64
4 Close 119 non-null float64
5 Volume 119 non-null int64
6 Market Cap 119 non-null int64
dtypes: datetime64[ns](1), float64(4), int64(2)
memory usage: 12.4 KBComo já é de nosso conhecimento, estamos trabalhando com 7 colunas:
- Date: representado o dia que os dados foram registrados
- Open: geralmente refere-se ao preço às 12:01 AM UTC
- High: valor máximo que o bitcoin atingiu nesse dia
- Low: valor mínimo que o bitcoin atingiu nesse dia
- Close: geralmente refere-se ao preço às 11:59 PM UTC
- Volume: refere-se ao volume de bitcoins negociados nesse dia
- Market Cap: capitalização de mercado - refere-se ao valor total de todas as ações de uma empresa
Iremos agora buscar o dia da semana referente a primeira linha de nosso DataFrame, para isso vamos contar com a ajuda de loc, capaz de acessar uma linha ou um grupo de linhas através de rótulos ou índices inteiros.
dados.loc[0]['Date'].day_name()o método day_name é responsável por nos retornar o dia da semana respectivo.
'Tuesday'Podemos então criar uma nova coluna em nossa DataFrame com o dia da semana respectivo de cada Date
dados['Week Day'] = dados['Date'].dt.day_name()Novamente utilizamos o método head() para visualizarmos o DataFrame
dados.head()Que nos retorna
| Date | Open | High | Low | Close | Volume | Market Cap | Week Day | |
|---|---|---|---|---|---|---|---|---|
| 0 | 2020-04-28 00:00:00 | 7796.97 | 7814.53 | 7730.81 | 7807.06 | 33187959921 | 143266252261 | Tuesday |
| 1 | 2020-04-27 00:00:00 | 7679.42 | 7795.6 | 7679.42 | 7795.6 | 36162144725 | 143040988590 | Monday |
| 2 | 2020-04-26 00:00:00 | 7570.14 | 7700.59 | 7561.41 | 7679.87 | 33070154491 | 140903867573 | Sunday |
| 3 | 2020-04-25 00:00:00 | 7550.48 | 7641.36 | 7521.67 | 7569.94 | 32941541447 | 138874072264 | Saturday |
| 4 | 2020-04-24 00:00:00 | 7434.18 | 7574.2 | 7434.18 | 7550.9 | 34636526286 | 138512029491 | Friday |
Como podemos observar, agora temos mais uma coluna em nosso DataFrame, chamada de Week Day.
Uma informação que pode ser útil para obtermos é a Data mais antiga na Série Temporal, para isso, podemos usar o método min()
dados['Date'].min()Que retornará Timestamp('2020-01-01 00:00:00'), respectivamente o dia 1 de janeiro de 2020.
Também podemos obter a Data mais recente com o auxílio do método max()
dados['Date'].max()Que retornará Timestamp('2020-04-28 00:00:00'), respectivamente o dia 28 de abril de 2020.
Podemos subtrair a data mais antiga da recente de forma a obtermos o intervalo de tempo
dados['Date'].max() - dados['Date'].min()O que nos retorna Timedelta('118 days 00:00:00')
Filtrando Dados
Os filtros nos permitem selecionarmos porções específicas de nosso DataFrame, por exemplo, podemos buscar somente os dias de Abril e adiante
filtro = (dados['Date'] >= 'April 2020')
dados.loc[filtro].head()Declaramos uma variável chamado de filtro e passamos ela para o loc que nos retornará somente as linhas que satisfazerem a condição determina por nós.
| Date | Open | High | Low | Close | Volume | Market Cap | Week Day | |
|---|---|---|---|---|---|---|---|---|
| 0 | 2020-04-28 00:00:00 | 7796.97 | 7814.53 | 7730.81 | 7807.06 | 33187959921 | 143266252261 | Tuesday |
| 1 | 2020-04-27 00:00:00 | 7679.42 | 7795.6 | 7679.42 | 7795.6 | 36162144725 | 143040988590 | Monday |
| 2 | 2020-04-26 00:00:00 | 7570.14 | 7700.59 | 7561.41 | 7679.87 | 33070154491 | 140903867573 | Sunday |
| 3 | 2020-04-25 00:00:00 | 7550.48 | 7641.36 | 7521.67 | 7569.94 | 32941541447 | 138874072264 | Saturday |
| 4 | 2020-04-24 00:00:00 | 7434.18 | 7574.2 | 7434.18 | 7550.9 | 34636526286 | 138512029491 | Friday |
Podemos também determinar múltiplas condições
filt = (dados['Date'] >= datetime(2020, 2, 1)) & (dados['Date'] < datetime(2020, 3, 1))
dados.loc[filt].head()Nesse caso, nos será retornado apenas as linhas referentes ao mês de fevereiro
| Date | Open | High | Low | Close | Volume | Market Cap | Week Day | |
|---|---|---|---|---|---|---|---|---|
| 59 | 2020-02-29 00:00:00 | 8671.21 | 8775.63 | 8599.51 | 8599.51 | 35792392544 | 156895988084 | Saturday |
| 60 | 2020-02-28 00:00:00 | 8788.73 | 8890.46 | 8492.93 | 8672.46 | 44605450443 | 158211707019 | Friday |
| 61 | 2020-02-27 00:00:00 | 8825.09 | 8932.89 | 8577.2 | 8784.49 | 45470195695 | 160238496932 | Thursday |
| 62 | 2020-02-26 00:00:00 | 9338.29 | 9354.78 | 8704.43 | 8820.52 | 50420050762 | 160879489024 | Wednesday |
| 63 | 2020-02-25 00:00:00 | 9651.31 | 9652.74 | 9305.02 | 9341.71 | 42515259129 | 170369581558 | Tuesday |
Vamos agora alterar o índice de nosso DataFrame para que ele seja a coluna Date, para esta tarefa vamos contar o ajuda do método set_index()
dados.set_index('Date', inplace=True)Podemos agora fazer consultas com mais facilidade, por exemplo, se desejarmos obter entradas somente para o mês de janeiro
dados['January 2020'].head()Obteremos como resultado
| Date | Open | High | Low | Close | Volume | Market Cap | Week Day |
|---|---|---|---|---|---|---|---|
| 2020-01-31 00:00:00 | 9508.31 | 9521.71 | 9230.78 | 9350.53 | 29432489719 | 170112778161 | Friday |
| 2020-01-30 00:00:00 | 9316.02 | 9553.13 | 9230.9 | 9508.99 | 32378792851 | 172978577931 | Thursday |
| 2020-01-29 00:00:00 | 9357.47 | 9406.43 | 9269.47 | 9316.63 | 30682598115 | 169460984603 | Wednesday |
| 2020-01-28 00:00:00 | 8912.52 | 9358.59 | 8908.45 | 9358.59 | 34398744403 | 170205617955 | Tuesday |
| 2020-01-27 00:00:00 | 8597.31 | 8977.73 | 8597.31 | 8909.82 | 28647338393 | 162027957435 | Monday |
O método mean é capaz de nos retornar a média dos valores para um determinado eixo, nesse caso, vamos obter a média do Close para o mês de Janeiro e Fevereiro.
dados['2020-02':'2020-01']['Close'].mean()Nos será retornado 8989.305166666665.
Podemos também, por exemplo, buscar o valor máximo do High para os 10 primeiros dias de janeiro
dados['2020-01-10':'2020-01-01']['High'].max()Nos será retornado 8396.74.
Gráficos
Pandas nos permite projetar gráficos através do método plot(), convenção para referenciarmos plt.plot() da biblioteca matplotlib.
Podemos por exemplo projetar as variações de High através de um gráfico de linhas
dados['High'].plot(figsize=(8,6), grid=True, c='k', linewidth=3)Que nos retorna o seguinte gráfico
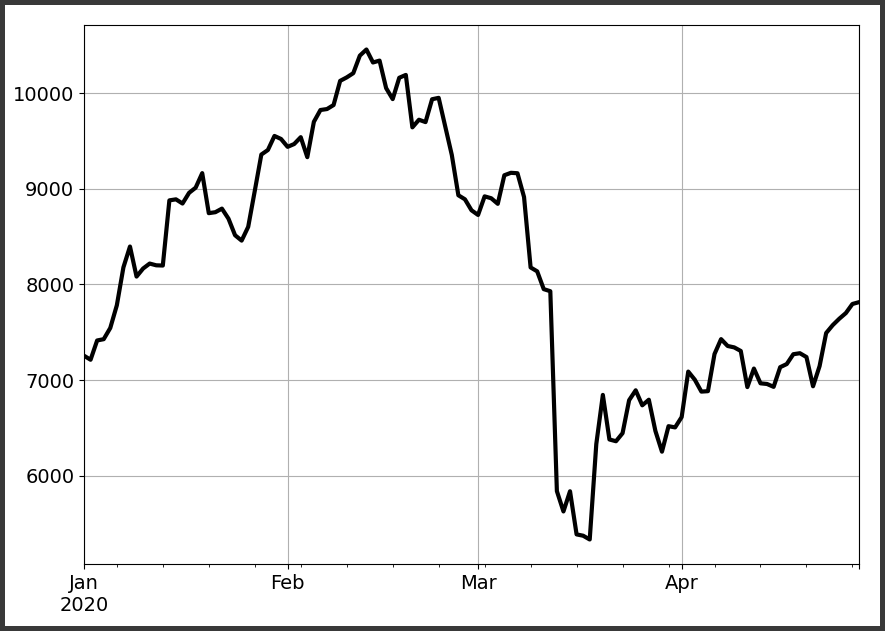
Também podemos projetar as variações do Market Cap
dados['Market Cap'].plot(figsize=(8,6), grid=True, c='g', linewidth=3)Que nos retorna o seguinte gráfico
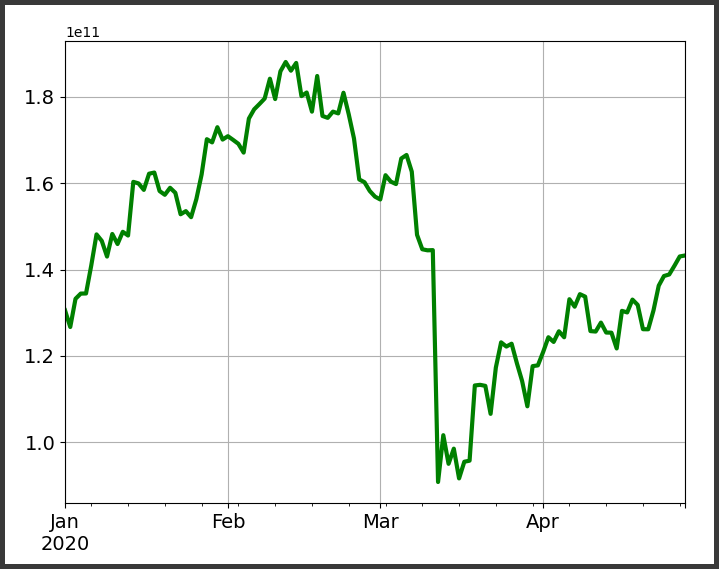
Reamostrando e Agregando
O método resample() tem o poder de Reamostrar dados de séries temporais, ele é conveniente para conversão de frequência e reamostragem de séries temporais. O objeto deve ter um índice semelhante a data e hora (DatetimeIndex, PeriodIndex ou TimedeltaIndex)
Uma parte essencial da análise de dados grandes é a sumarização eficiente: agregações de computações como sum(), mean(), median(), min() e max(), nas quais um único número fornece informações sobre a natureza de um potencialmente grande conjunto de dados.
O método agg() é capaz de agregar utilizando uma ou mais operações sob um eixo especificado.
Vejamos como podemos reamostrar nossa Série Temporal de forma que Date seja agrupado semanalmente.
dados.resample('W').agg({'Close': 'mean', 'High': 'max', 'Low': 'min'})Também utilizamos o método agg() e passamos para ele um dicionário com os métodos que desejamos executar para cada eixo:
- Close obteremos a média para cada semana
- High obteremos o valor máximo para cada semana
- Low obteremos o valor mínimo para cada semana
Teremos como retorno o seguinte DataFrame
| Date | Close | High | Low |
|---|---|---|---|
| 2020-01-05 00:00:00 | 7270.5 | 7544.5 | 6915 |
| 2020-01-12 00:00:00 | 8041.2 | 8396.74 | 7409.29 |
| 2020-01-19 00:00:00 | 8725.84 | 9164.36 | 8079.7 |
| 2020-01-26 00:00:00 | 8557.29 | 8792.99 | 8266.84 |
| 2020-02-02 00:00:00 | 9311.69 | 9553.13 | 8597.31 |
| 2020-02-09 00:00:00 | 9656.49 | 10129.4 | 9112.81 |
| 2020-02-16 00:00:00 | 10105.9 | 10457.6 | 9722.39 |
| 2020-02-23 00:00:00 | 9764.02 | 10191.7 | 9507.64 |
| 2020-03-01 00:00:00 | 8918.76 | 9951.75 | 8471.21 |
| 2020-03-08 00:00:00 | 8804.58 | 9167.7 | 8105.25 |
| 2020-03-15 00:00:00 | 6410.28 | 8177.79 | 4106.98 |
| 2020-03-22 00:00:00 | 5697.69 | 6844.26 | 4575.36 |
| 2020-03-29 00:00:00 | 6454.66 | 6892.51 | 5785 |
| 2020-04-05 00:00:00 | 6665.85 | 7088.25 | 5903.23 |
| 2020-04-12 00:00:00 | 7111.43 | 7427.94 | 6782.89 |
| 2020-04-19 00:00:00 | 6998.52 | 7280.52 | 6555.5 |
| 2020-04-26 00:00:00 | 7301.42 | 7700.59 | 6834.44 |
| 2020-05-03 00:00:00 | 7801.33 | 7814.53 | 7679.42 |
Nos mostrando um resumo semanal interessante de nossos dados e concluindo o tutorial.
Conclusão
Durante este breve estudo e experimente estivemos aptos a compreender aspectos fundamentais das Séries Temporais e sua importância prática no mundo científico.
Também fomos capazes de fazer análises simples em um conjunto de dados sobre a criptomoeda Bitcoin, além de visualizar gráficos e aplicar aggregations.
Para mais detalhes verifique a documentação das ferramentas e as referências.