
Conteúdo
Breve Histórico
O desenvolvimento do HTTP foi iniciado por Tim Berners-Lee no CERN em 1989. O desenvolvimento inicial dos HTTP Requests for Comments (RFCs) foi um esforço coordenado pela Internet Engineering Task Force (IETF) e pelo World Wide Web Consortium (W3C), posteriormente movido para o IETF.
Introdução
O Hypertext Transfer Protocol (HTTP) é a base de qualquer troca de dados na Web e é um protocolo cliente-servidor, o entendimento de seu funcionamento é essencial para desenvolvermos aplicações eficientes e de qualidade.
HTTP é um protocolo sem estado. Em outras palavras, a solicitação atual não sabe o que foi feito nas solicitações anteriores.
O protocolo HTTP é um protocolo de requisição/resposta.
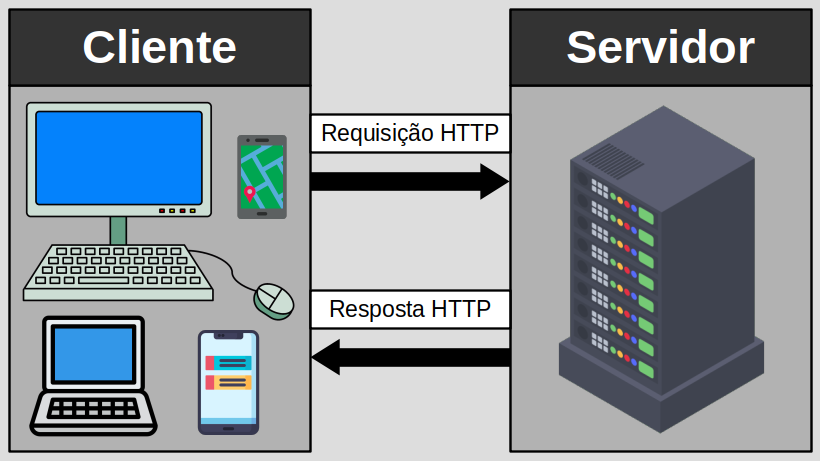
Um cliente envia uma requisição ao servidor na forma de um método de requisição, URI e versão do protocolo, seguido por uma mensagem semelhante a MIME contendo modificadores de requisição, informações do cliente e possível conteúdo do corpo através de uma conexão com um servidor.
O servidor responde com uma linha de status, incluindo a versão do protocolo da mensagem e um código de sucesso ou erro, seguido por uma mensagem semelhante a MIME contendo informações do servidor, informações sobre metainformações e possível conteúdo do corpo da entidade.
Cliente
Um navegador da web, por exemplo, pode ser o cliente e um aplicativo em execução em um computador que hospeda um site pode ser o servidor. O cliente envia uma mensagem de solicitação HTTP ao servidor. O servidor, que fornece recursos como arquivos HTML e outro conteúdo, ou executa outras funções em nome do cliente, retorna uma mensagem de resposta ao cliente. A resposta contém informações de status de conclusão sobre a solicitação e também pode conter conteúdo solicitado em seu corpo da mensagem.
Um navegador da web é um exemplo de um user agent(UA). Outros tipos de user agent incluem o software de indexação usado por provedores de pesquisa (Web Crawlers), navegadores de voz, aplicativos móveis e outro software que acesse, consuma ou exiba conteúdo da Web.
O HTTP foi projetado para permitir que elementos de rede intermediários melhorem ou habilitem as comunicações entre clientes e servidores. Os sites de alto tráfego geralmente se beneficiam dos servidores de cache da web que fornecem conteúdo em nome dos servidores upstream para melhorar o tempo de resposta. Os navegadores da Web armazenam em cache os recursos da Web acessados anteriormente e os reutilizam, quando possível, para reduzir o tráfego da rede.
Para apresentar uma página da Web, o navegador envia uma solicitação original para buscar o documento HTML que representa a página. Em seguida, ele analisa esse arquivo, fazendo solicitações adicionais correspondentes a scripts de execução, informações de layout (CSS) a serem exibidas e sub-recursos contidos na página (geralmente imagens e vídeos). O navegador da Web combina esses recursos para apresentar ao usuário um documento completo, a página da Web. Os scripts executados pelo navegador podem buscar mais recursos em fases posteriores e o navegador atualiza a página da Web de acordo.
Uma página da Web é um documento de hipertexto. Isso significa que algumas partes do texto exibido são links que podem ser ativados (geralmente com um clique do mouse) para buscar uma nova página da Web, permitindo que o usuário direcione seu agente e navegue pela Web.
Servidor
No lado oposto do canal de comunicação, está o servidor, que serve o documento conforme solicitado pelo cliente. Um servidor aparece apenas como uma única máquina virtualmente: mas na verdade pode ser realmente uma coleção de servidores, compartilhando a carga (balanceamento de carga) ou um software complexo que interroga outros computadores(como cache, servidor de banco de dados ou servidores de comércio eletrônico), totalmente ou parcialmente gerando o documento sob demanda.
Um servidor não é necessariamente uma única máquina, mas várias instâncias de softwares de servidor podem ser hospedadas na mesma máquina. Com o HTTP/1.1 e o cabeçalho Host, eles podem até compartilhar o mesmo endereço IP.
Proxies
Entre o navegador da Web e o servidor, vários computadores e máquinas retransmitem as mensagens HTTP. Devido à estrutura organizacional em camadas dos protocolos da Web, a maioria delas opera nos níveis de transporte, rede ou físico, tornando-se transparente na camada HTTP e potencialmente causando um impacto significativo no desempenho. Aqueles que operam nas camadas de aplicação são geralmente chamados de proxies. Eles podem ser transparentes, encaminhando as solicitações recebidas sem alterá-las de qualquer forma ou não transparentes, nesse caso, eles alterarão a solicitação de alguma forma antes de transmiti-la ao servidor. Os proxies podem executar várias funções, tais como:
- caching (o cache pode ser público ou privado, como o cache do navegador)
- filtering (como uma verificação antivírus)
- load balancing (para permitir que vários servidores atendam a diferentes solicitações)
- authentication (para controlar o acesso a diferentes recursos)
- logging (para permitir o armazenamento de informações históricas)
Requisição HTTP
Uma mensagem de solicitação de um cliente para um servidor inclui dentro da primeira linha dessa mensagem, o método a ser aplicado ao recurso HTTP, o identificador do recurso(Request-URI) e a versão do protocolo em uso.
Métodos HTTP
O HTTP define métodos para indicar a ação desejada a ser executada no recurso identificado. O que esse recurso representa, sejam dados preexistentes ou gerados dinamicamente, depende da implementação do servidor. Freqüentemente, o recurso corresponde a um arquivo ou à saída de um executável que reside no servidor.
O token do método indica o método a ser executado no recurso identificado pelo Request-URI. O método diferencia maiúsculas de minúsculas.
A especificação/versão HTTP/1.0 definiu os métodos GET, HEAD e POST e a especificação HTTP/1.1 adicionou cinco novos métodos: OPTIONS, PUT, DELETE, TRACE e CONNECT.
GET
Um cliente pode usar a requisição GET para obter um recurso da Web do servidor. É utlizado quando você digita um URL na barra de endereços do navegador ou quando clica em um link.
Ele pede ao servidor para enviar o recurso solicitado como resposta.
HEAD
O método HEAD solicita uma resposta idêntica à de uma solicitação GET, mas sem o corpo da resposta. Isso é útil para recuperar as metainformações gravadas nos cabeçalhos de resposta, sem precisar transportar todo o conteúdo.
POST
O método POST solicita que o servidor aceite a entidade incluída na solicitação como um novo subordinado do recurso da web identificado pelo URI. Os dados POSTADOS podem ser, por exemplo: uma mensagem para um quadro de avisos, grupo de notícias, lista de discussão ou tópico de comentário, um bloco de dados que é o resultado do envio de um formulário da web para um processo de tratamento de dados, ou um item para adicionar em um banco de dados.
Resumidamente, o cliente usa o método POST para enviar dados para o servidor. É normalmente usado em formulários, por exemplo, mas também ao interagir com REST API’s.
OPTIONS
O método OPTIONS retorna os métodos HTTP que o servidor suporta para a URI especificada. Isso pode ser usado para verificar a funcionalidade de um servidor da web solicitando ’*’ em vez de um recurso específico.
PUT
O método PUT requisita que a entidade encapsulada seja armazenada no URI fornecido. Se o URI se referir a um recurso já existente, ele é modificado; se o URI não apontar para um recurso existente, o servidor poderá criar o recurso com esse URI.
DELETE
O método DELETE é chamado em uma URI para solicitar a exclusão desse recurso. Usado principalmente em REST API’s
TRACE
O método TRACE solicita ao servidor para retornar um rastreamento de diagnóstico das ações executadas. Usado para fins de debugging ou diagnóstico.
CONNECT
Usado para dizer a um proxy para fazer uma conexão com outro host e simplesmente responder o conteúdo, sem tentar analisá-lo ou armazená-lo em cache. Isso geralmente é usado para fazer a conexão SSL através de um proxy.
Recursos HTTP
O conceito de recurso da Web evoluiu durante o histórico da Web, desde a noção inicial de documentos ou arquivos estáticos endereçáveis, até uma definição mais genérica e abstrata, agora abrangendo todas as “coisas” ou entidades que podem ser identificadas, nomeadas, endereçadas ou manipuladas, de qualquer forma, na Web em geral ou em qualquer sistema de informações em rede.
Os recursos HTTP são identificados e localizados na rede pelos URL’s(Uniform Resource Locators), usando os esquemas HTTP e HTTPS dos URI’s(Uniform Resource Identifiers).
Identificador do Recurso URI
Um URI(Uniform Resource Identifier) é uma sequência de caracteres que identifica inequivocamente um recurso específico. Para garantir uniformidade, todos os URI’s seguem um conjunto predefinido de regras de sintaxe, mas também mantêm a extensibilidade por meio de um esquema de nomeação hierárquico definido separadamente.
Tal identificação permite a interação com representações do recurso em uma rede, geralmente na World Wide Web, usando protocolos específicos. Esquemas especificando uma sintaxe concreta e protocolos associados definem cada URI. A forma mais comum de URI é o URL(Uniform Resource Locator), frequentemente referido informalmente como um endereço web. Mais raramente visto em uso é o Uniform Resource Name (URN), que foi projetado para complementar URLs, fornecendo um mecanismo para a identificação de recursos em determinados espaços de nomes.
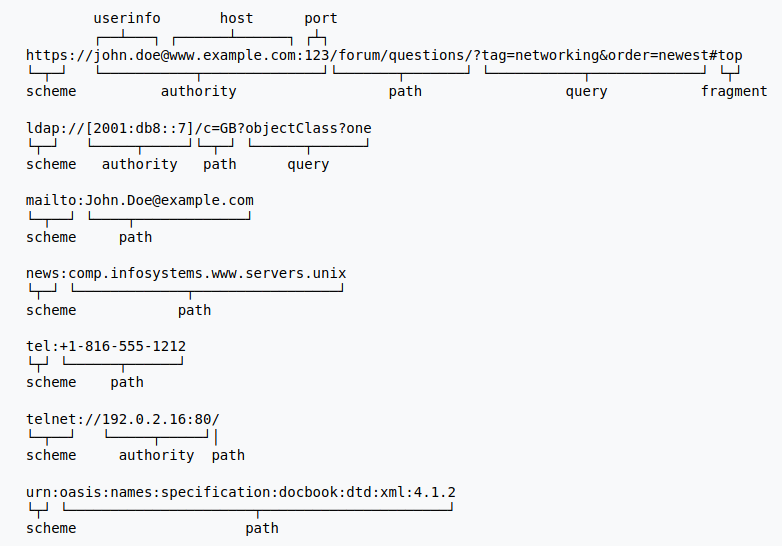
A sintaxe genérica do URI consiste em uma sequência hierárquica de cinco componentes
URI = scheme:[//authority]path[?query][#fragment]onde o componente de authority se divide em três subcomponentes:
authority = [userinfo@]host[:port]Isso pode ser representado através do diagrama de síntaxe:

O URI compreende então:
- Scheme: Um componente scheme não vazio seguido por dois pontos (:), consistindo em uma sequência de caracteres começando com uma letra e seguido por qualquer combinação de letras, dígitos, mais (+), ponto (.) Ou hífen (-). Embora os schemes não diferenciam maiúsculas de minúsculas, o formato canônico é minúsculo e os documentos que especificam os esquemas devem fazê-lo com letras minúsculas. Exemplos de esquemas populares incluem http, https, ftp, mailto, file, data e irc.
-
Authority: Um componente authority opcional precedido por duas barras (//), compreendendo:
- userinfo: Um subcomponente opcional userinfo que pode consistir em um nome de usuário e uma senha opcional precedidos por dois pontos (:), seguidos por um símbolo de arroba (@).
- host: Um subcomponente host, consistindo de um nome registrado (incluindo, sem limitação, um nome de host) ou um endereço IP. Os endereços IPv4 devem estar em notação decimal com ponto e os endereços IPv6 devem estar entre colchetes([]).
- port: Um subcomponente port opcional precedido por dois pontos (:).
- Path: Um componente path, consistindo em uma sequência de segmentos de caminho separados por uma barra (/). Um caminho é sempre definido para um URI, embora o caminho definido possa estar vazio (comprimento zero). Um segmento também pode estar vazio, resultando em duas barras consecutivas (//) no componente de caminho.
- Query: Um componente query opcional precedido por um ponto de interrogação (?), Contendo uma sequência de consultas de dados não hierárquicos. Sua sintaxe não está bem definida, mas, por convenção, geralmente é uma sequência de pares atributo-valor separados por um delimitador.
- Fragment: Um componente fragment opcional precedido por um hash (#). O fragmento contém um identificador de fragmento que fornece orientação para um recurso secundário, como um cabeçalho de seção em um artigo identificado pelo restante do URI. Quando o recurso principal é um documento HTML, o fragmento geralmente é um atributo de identificação de um elemento específico, e os navegadores da Web rolam esse elemento para exibição.
Unindo tudo em diversos exemplos:
Linha de Requisição
A linha de requisição começa com um token de método, seguido pelo URI de solicitação e a versão do protocolo e termina com CRLF. Os elementos são separados por caracteres SP. Nenhum CR ou LF é permitido, exceto na sequência CRLF final.
Vejamos alguns exemplos:
GET /index.html HTTP/1.1
HEAD /teste.html HTTP/1.0
POST /filmes HTTP/1.1Linha de Status
A primeira linha é chamada de linha de status, seguida pelos cabeçalhos de resposta opcionais.
Exemplos da linha de status:
HTTP/1.1 200 OK
HTTP/1.0 404 Not Found
HTTP/1.1 403 ForbiddenPara ver a lista de todos os status codes, visite The HTTP Status Codes List
Cabeçalhos de Requisição
Os cabeçalhos da requisição funcionam na forma de pares -> nome:valor. Múltiplos valores, separados por vírgulas, podem ser especificados.
Por exemplo:
Host: www.tibia.com
Connection: Keep-Alive
Accept: image/gif, image/jpeg, */*
Accept-Language: us-en, fr, cnPara ver a lista de todos os cabeçalhos você pode visitar este link
Cabeçalhos de Resposta
Os cabeçalhos de resposta funcionam na forma de pares de nome:valor.
Por exemplo:
Content-Type: text/html
Content-Length: 35
Connection: Keep-Alive
Keep-Alive: timeout=15, max=100No corpo da mensagem da resposta está contido o recursos/dados solicitados
Para ver a lista de todos os cabeçalhos você pode visitar este link
Comunicação HTTP Cliente/Servidor
Para executarmos uma comunicação HTTP é necessário que tenhamos um user agent que é um software que atua em nome de um usuário, como um navegador da Web que busca, renderiza e facilita a interação do usuário final com o conteúdo da Web. Além de Web Browsers podemos utilizar outras ferramentas e até mesmo linguagens de programação para interagirmos com recursos da Web.
Vejamos alguns exemplos a seguir:
A Ferramenta Curl
curl é usado em linhas de comando ou scripts para transferir dados. Também é usado em carros, aparelhos de televisão, roteadores, impressoras, equipamentos de áudio, telefones celulares, tablets, decodificadores, tocadores de mídia e é a espinha dorsal da transferência da Internet para milhares de aplicativos que afetam bilhões de seres humanos diariamente.
curl -i https://akirablog.surge.shNos será retornado:
HTTP/1.1 200 OK
Server: SurgeCDN/1.3.0
Date: Sat, 22 Feb 2020 10:25:11 GMT
Cache-Control: public, max-age=31536000, no-cache
ETag: "978b19833043fea676af62f974e6257b"
Content-Type: text/html; charset=UTF-8
Accept-Ranges: bytes
Response-Time: 3ms
Content-Length: 29824
Vary: Accept-Encoding
Connection: close
<!DOCTYPE html>
<html lang="en">
<head>
<meta charSet="utf-8"/>
...GNU Wget
Wget é um programa de computador que recupera conteúdo de servidores da web. Faz parte do projeto GNU. Seu nome deriva da World Wide Web e get. Ele suporta o download via HTTP, HTTPS e FTP.
Baixando todo o conteúdo Front-End de um website
wget -r https://akirablog.surge.shPython
No Python podemos utilizar a biblioteca Requests, que é uma biblioteca HTTP elegante e simples para Python, criada para seres humanos.
# Importamos a biblioteca em nosso script
import requests
# Executamos o GET request
requisicao = requests.get('https://akirablog.surge.sh')
# Imprimimos o status code de nossa requisição, 200 se for sucesso
print(requisicao.status_code)
# Imprimimos o conteúdo HTML retornado pelo servidor
print(requisicao.text) Javascript
É muito comum fazermos requisições HTTP na linguagem Javascript, seja de forma síncrona ou assíncrona. Vamos abrir o console de nosso navegador e experimentar alguns scripts:
Vamos criar a seguinte função, que fará uma requisição síncrona para uma URL, através do uso do objeto XMLHttpRequest
function getRequest(url){
let xmlHttp = new XMLHttpRequest()
xmlHttp.open("GET", url, false)
xmlHttp.send(null)
return xmlHttp.responseText
}Vamos agora utilizar a nossa função para solicitar dados a uma API:
getRequest('https://jsonplaceholder.typicode.com/posts')Observe que será retornado um array de objetos que representam posts. No entanto, solicitações síncronas são desencorajadas e geram um aviso de atenção.
Vejamos como podemos fazer requisições assíncronas, definiremos uma função que fará uma requisição para a API do GitHub e nos retornará uma resposta com os dados em JSON do usuário escolhido por nós:
async function getGitUser(nome) {
let resposta = await fetch(`https://api.github.com/users/${nome}`)
let dados = await resposta.json()
return dados
}Vamos agora invocar nossa função passando como argumento o nome do usuário que desejamos buscar:
getGitUser('the-akira').then(dados => console.log(dados))A função nos retorna uma promise, que por sua vez nos permite acessarmos os dados da API.
Conclusão
Através desse pequeno artigo foi possível observarmos o tamanho da importância do protocolo HTTP em relação ao Desenvolvimento Web e o próprio funcionamento da World Wide Web, é através dele que podemos nos comunicar com bilhões de recursos disponíveis em servidores espalhados por todo o Globo e é fundamental que tenhamos o entendimento do seu funcionamento e a forma com que ele vem evoluindo.