![]()
Conteúdo
- Introdução
- Por que Machine Learning?
- Tipos de Sistemas de Machine Learning
- Desafios do Machine Learning
- Testando e Validando
- Scikit-Learn
- Projeto
- Machine Learning Workflow
- Conclusão
- Referências
Introdução
Machine Learning é a ciência (e arte) de programar computadores de forma que eles sejam capazes de aprender através de dados.
Os autores Arthur Samuel e Tom Mitchell definem Machine Learning como:
"Machine Learning é o campo de estudo que fornece aos computadores a habilidade de aprender sem que eles sejam explicitamente programados."
"Um computador é dito aprender através de uma experiência E em respeito a uma tarefa T e uma medida de perfomance P, se sua perfomance em T, medida por P, melhorar com a experiência E."
Podemos por exemplo considerar a tarefa de reconhecimento de emails como Regulares ou Spam:
- Tarefa T: Separar emails em categorias (Exemplo: Regular / Spam)
- Medida de Perfomance P: Soma ponderada de erros, Matriz de Confusão
- Experiência E: Dados de emails, rotulados como Regular ou Spam
Por que Machine Learning?
Machine Learning é grandioso na solução de problemas como:
- Aqueles no qual soluções existentes requerem muito trabalho manual ou longas listas de regras: nesse caso um algoritmo de Machine Learning pode muitas vezes simplificar o código e oferecer uma solução com melhor performance.
- Problemas complexos ao qual não há uma boa solução usando a programação tradicional: as melhores técnicas de Machine Learning podem encontrar uma solução.
- Ambientes flutuantes: Um sistema de Machine Learning pode se adaptar a novos dados.
- Obter insights sobre problemas complexos e grandes quantidades de dados.
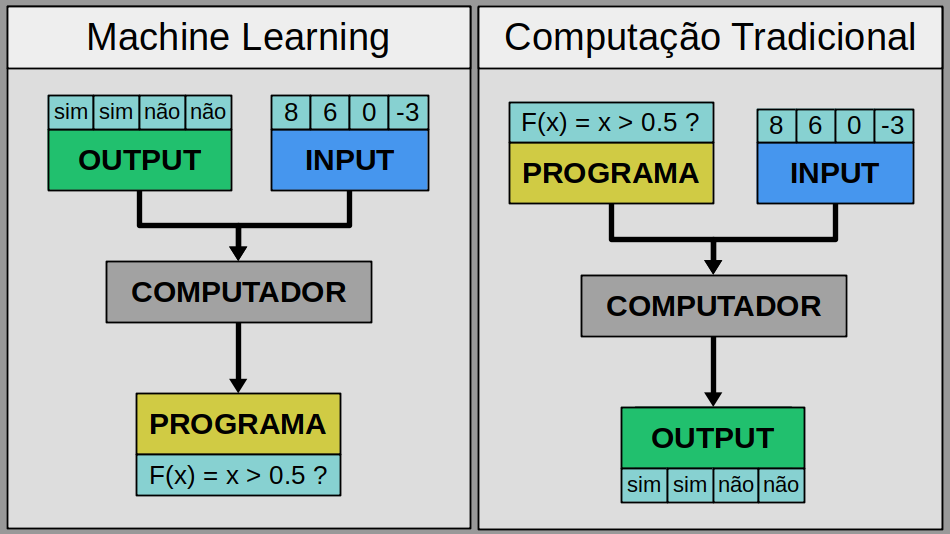
Tipos de Sistemas de Machine Learning
Existem diferentes tipos de sistemas de Machine Learning, podemos classificá-los em categorias como:
-
Se eles são ou não treinados com a supervisão humana:
- Supervised Learning - (Aprendizado Supervisionado)
- Unsupervised Learning - (Aprendizado Não-Supervisionado)
- Semisupervised Learning - (Aprendizado Semi-Supervisionado)
- Reinforcement Learning - (Aprendizado por Reforço)
-
Se eles conseguem ou não aprender de forma incremental:
-
Se eles funcionam através da simples comparação de novos pontos de dados com pontos de dados já conhecidos, ou ao invés disso detecta padrões nos dados de treinamento e constrói um modelo preditivo, similar como cientistas fazem:
Esses critérios não são exclusivos, eles podem ser combinados da maneira que desejarmos. Por exemplo, um filtro de spams eficiente pode aprender em tempo real utilizando um modelo de rede neural artificial treinado utilizando exemplos de email SPAM e REGULAR, isso torna ele Online, Model-Based e um sistema Supervised Learning.
Para entendermos melhor, vejamos em mais detalhes os diferentes tipos de aprendizado.
Supervised Learning
No Aprendizado Supervisionado, os dados de treinamento que alimentamos no algoritmo incluem as soluções desejadas, também conhecidas como rótulos.
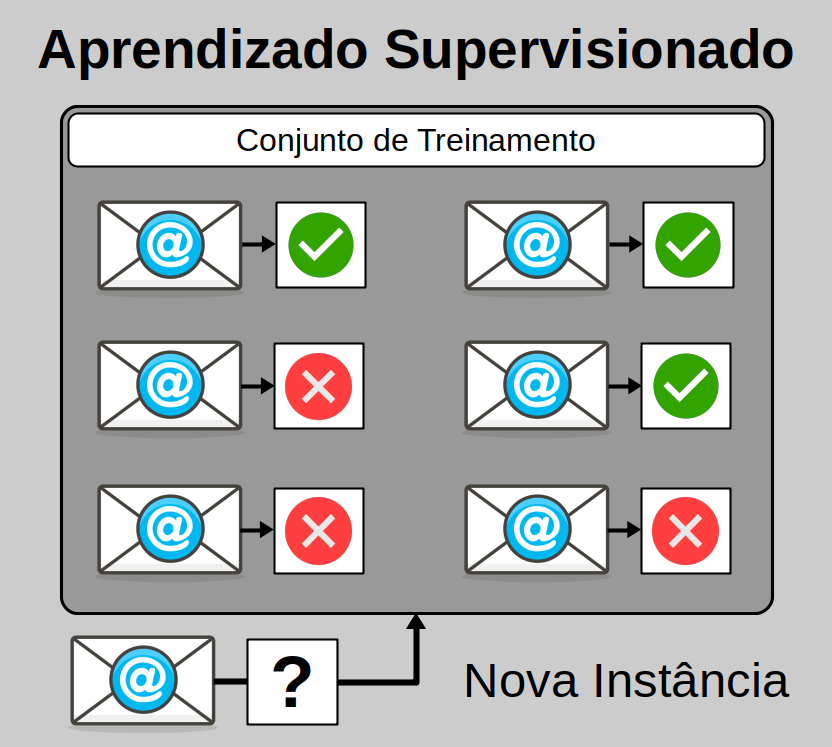
Uma tarefa supervisionada comum é a classificação. O filtro de spam que citamos é um bom exemplo: ele é treinado com muitos exemplos de emails juntamente com suas respectivas classes (SPAM ou REGULAR) e assim deve aprender como classificar novos emails até então não vistos por ele.
Outra tarefa comum é prever um valor numérico alvo, como por exemplo o preço de uma casa, dado um conjunto de features (tamanho, localização, conservação) chamados de predictors. Esse tipo de tarefa é conhecida como regressão. Para treinarmos o sistema é necessaŕio fornecer a ele muitos exemplos de casas, incluindo os predictors e seus rótulos (preço das casas).
Exemplos de importantes algoritmos de Supervised Learning:
- k-Nearest Neighbors
- Linear Regression
- Logistic Regression
- Support Vector Machines (SVMs)
- Decision Trees e Random Forests
Unsupervised Learning
No Aprendizado Não-Supervisionado, como podemos imaginar, os dados de treinamento não são rotulados. O sistema tenta aprender sem o auxílio de um professor.

Por exemplo, digamos que temos uma grande quantidade de dados sobre computadores e desejamos agrupá-los em grupos que possuam similaridade, para isso podemos usar um algoritmo de clustering, e este pode eventualmente separar os computadores em grupos, possivelmente divididos por perfomance/eficiência.
Algoritmos de visualização também são um bom exemplo de algoritmos Unsupervised Learning: alimentamos a ele muitos dados complexos e não-rotulados e ele nos oferece como output uma representação 2D ou 3D dos dados que podem ser facilmente projetadas.
Uma tarefa relacionada é a de dimensionality reduction, ao qual o objetivo é simplificar os dados sem que haja perda de informação. Uma maneira de executar essa tarefa é através da união de diversas features correlacionados em um. Por exemplo, a kilometragem de um carro pode estar correlacionada com a sua idade, sendo assim, o algoritmo de redução de dimensionalidade irá uní-los em apenas uma feature.
Semisupervised Learning
Alguns algoritmos podem lidar com dados de treinamento parcialmente rotulados, normalmente muitos dados não-rotulados e um pouco de dados rotulados.
Um exemplo citado pelo autor Aurélien Géron cita os serviços de hospedagem de photos que são capazes de reconhecer a presença de pessoas nas fotografias e marcá-las automaticamente através do aprendizado de marcações anteriores feitas por nós.
Reinforcement Learning
O Reinforcement Learning é complementa diferente dos outros. O sistema de aprendizado nesse caso é chamado de agente e tem a capacidade de observar o ambiente, selecionar e executar ações e obter recompensas (ou penalizações na forma de recompensas negativas). Ele então deve aprender por si mesmo qual é a melhor estratégia, chamado de política, de forma a receber o máximo de recompensa. A política define qual ação o agente deve escolher quando estiver em uma determinada situação.
Como exemplo podemos citar os robôs, muitos deles implementam algoritmos de Reinforcement Learning para aprenderem a caminhar. O AlphaGo Deepmind é um excelente exemplo de Reinforcement Learning, ele ficou muito conhecido em maio de 2017 quando venceu o campeão mundial Ke Jie no jogo Go, ele aprendeu sua política de vitória ao analisar milhões de jogos e posteriormente jogar muitos jogos contra si mesmo.
Batch Learning
Em Batch Learning, o sistema é incapaz de aprender de forma incremental: ele deve ser treinado utilizando todos os dados disponíveis. Isso normalmente tomará bastante tempo e recursos computacionais, então é feito tipicamente offline. Primeiro o sistema é treinado, depois ele é lançado para produção e roda sem mais aprender, ele apenas aplica o que já aprendeu. Isso é chamado de offline learning.
Online Learning
No Online Learning o sistema é treinado de maneira incremental ao alimentarmos instâncias de dados sequencialmente, ou individualmente ou através de grupos menores conhecidos como mini-batches. Cada passo de aprendizado é rápido e pouco custoso, então o sistema pode aprender sobre novos dados em tempo real.
Instance-Based vs Model-Based Learning
Uma outra maneira de categorizar os sistemas de Machine Learning é como eles generalizam. Muitas tarefas de Machine Learning são sobre fazer previsões. Isso significa que dado um número de exemplos de treinamento, o sistema precisa estar apto a generalizar para exemplos que nunca viu antes. Ter uma boa perfomance nos dados de treinamento é bom, mas isso é insuficiente, o verdadeiro objetivo é termos uma perfomance boa em novas instâncias.
Instance-Based Learning
É uma família de algoritmos de aprendizado que, em vez de executar generalização explícita, compara novas instâncias de problemas com instâncias vistas em treinamento, que foram armazenadas na memória.
Exemplos de algoritmos Instance-Based Learning são o algoritmo k-nearest neighbors, kernel machines e redes RBF. Estes armazenam (um subconjunto) de seu conjunto de treinamento; ao prever um valor/classe para uma nova instância, eles calculam distâncias ou similaridades entre essa instância e as instâncias de treinamento para tomar uma decisão.
Model-Based Learning
A idéia central da abordagem Model-Based para o Machine Learning é criar um modelo personalizado, personalizado especificamente para cada nova aplicação. Em alguns casos, o modelo (junto com um algoritmo de inferência associado) pode corresponder a uma técnica tradicional de Machine Learning, enquanto em muitos casos não.
Desafios do Machine Learning
Considerando que nossas principais tarefas são: Selecionar um algoritmo de aprendizado e treiná-lo com uma certa quantidade de dados, nesse caso, o que poderia dar errado seria a escolha do algoritmo ou do conjunto de dados. Vejamos alguns exemplos:
- Quantidade insuficiente de dados de treinamento
- Dados de treinamento não-representativos
- Qualidade pobre dos dados
- Features irrelevantes
- Overfitting dos dados de treinamento
- Underfitting dos dados de treinamento
Testando e Validando
Uma forma eficaz de testarmos e validarmos nossos modelos é através da divisão dos dados em dois conjuntos: um conjunto de treinamento e um conjunto de teste. Utilizaremos o conjunto de treinamento para treinarmos o modelo e testaremos ele com o conjunto de teste. A taxa de erro em novos casos é chamada de erro de generalização, ao avaliarmos o modelo no conjunto de testes, obteremos uma estimativa desse erro. Esse valor irá nos dizer quão bem o modelo será capaz de performar em instâncias que nunca viu antes.
Se o erro de treinamento é baixo (o modelo comete poucos erros no conjunto de treinamento), porém o erro de generalização é alto, isso significa que o modelo está overfitting os dados de treinamento.
Overfitting é o uso de modelos ou procedimentos que violam Occam’s razor, por exemplo, incluindo parâmetros mais ajustáveis do que o ideal, ou usando uma abordagem mais complicada do que o ideal.
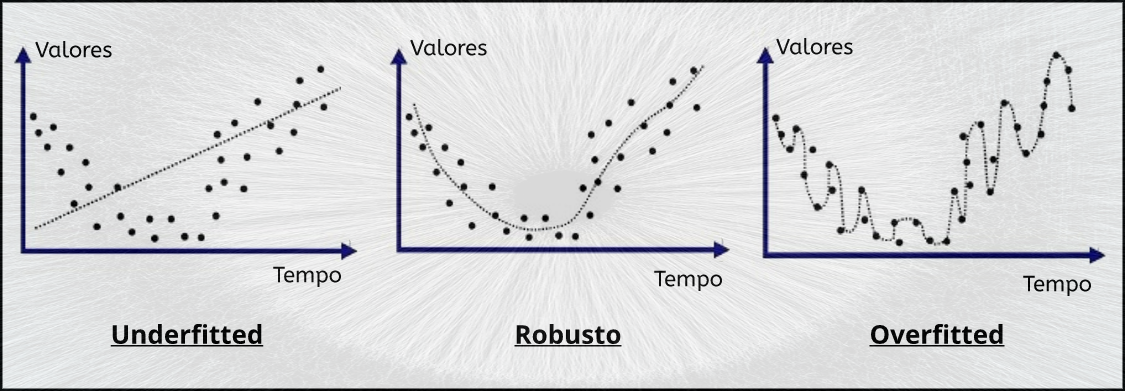
Underfitting ocorre quando um modelo estatístico ou algoritmo de Machine Learning não pode capturar adequadamente a estrutura subjacente dos dados. Ocorre quando o modelo ou algoritmo não se ajusta aos dados o suficiente. O Underfitting ocorre se o modelo/algoritmo mostrar baixa variance, mas alto bias (para contrastar com o oposto, Overfitting da alta variance e baixo bias). Geralmente, é o resultado de um modelo excessivamente simples.
É de comum prática utilizar 80% dos dados para treinamento e manter 20% para teste.
Considere ler sobre o no free lunch theorem.
Scikit-Learn
![]()
Scikit-Learn é software livre de Machine Learning, especificamente uma biblioteca para a linguagem de programação Python. Conta com diversos algoritmos para tarefas como: classificação, regressão e clusterização, incluindo Support Vector Machines, Random Forests, gradient boosting, k-means, DBSCAN e diversos outros. É projetada para interoperar com as bibliotecas numéricas e científicas Python: NumPy e SciPy.
Scikit-Learn também é capaz de integrar muito bem com diveras outras bibliotecas Python, como matplotlib e plotly para projeção de gráficos, pandas para dataframes.
Projeto
Uma vez que estamos familiarizados com conceitos importantes de Machine Learning e já temos uma ferramenta poderosa em mãos, podemos finalmente escolher nosso conjunto de dados para trabalharmos, que nesse caso será o Iris flower data set.
Conjunto de Dados Iris
O conjunto de dados de flores íris ou o conjunto de dados da íris de Fisher é um conjunto de dados multivariado introduzido pelo estatístico e biólogo britânico Ronald Fisher em seu artigo de 1936 entitulado “The use of multiple measurements in taxonomic problems as an example of linear discriminant analysis”.
O conjunto de dados consiste em 50 amostras de cada uma das três espécies de Iris (Iris setosa, Iris virginica e Iris versicolor). Quatro features foram medidas em cada amostra: o comprimento e a largura das sépalas e pétalas, em centímetros. Com base na combinação dessas quatro features, Fisher desenvolveu um modelo discriminante linear para distinguir as espécies umas das outras.

O conjunto de dados contém no total um conjunto de 150 registros, sob cinco atributos: comprimento da pétala, largura da pétala, comprimento da sépala, largura da sépala e espécie da flor.
Com base no modelo discriminante linear de Fisher, esse conjunto de dados se tornou um caso de teste típico para muitas técnicas de classificação estatística em Machine Learning, como Support Vector Machines por exemplo.
Há quem diga que a classificação das flores Iris é o Hello World do Machine Learning, ele é um excelente projeto para iniciarmos pelo fato dos dados já estarem prontos para trabalharmos, nos possibilitando experimentar diversos algoritmos sem um grande custo computacional.
Machine Learning Workflow
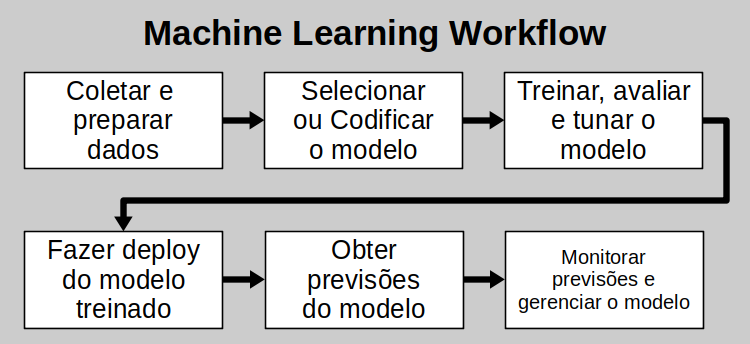
Para este projeto, seguiremos um modelo similar a este:
- Instalação das bibliotecas necessárias
- Carregamento do conjunto de dados
- Sumarização do conjunto de dados
- Visualização do conjunto de dados
- Avaliação de dois algoritmos
- Execução de previsões
Instalando Bibliotecas
Primeiramente é essencial que você tenha a linguagem Python em sua máquina. Uma vez que temos o Python, ganhamos acesso ao pip que nos permite instalar Third-Party Tools.
Vamos então abrir a Command-Line Interface e digitar os seguintes comandos:
pip install pandas
pip install matplotlib
pip install scikit-learnUma vez instaladas, podemos consultar suas versões através do seguinte código:
import sklearn
import matplotlib
import pandas
print(sklearn.__version__)
print(matplotlib.__version__)
print(pandas.__version__)Para este tutorial estou utilizando: Scikit-Learn 0.22.1, Matplotlib 3.1.3 e Pandas 1.0.3.
Importando Módulos Necessários
Agora que já estamos cientes a respeito das versões de cada ferramenta, podemos iniciar importando os módulos que iremos trabalhar, para este projeto escolhi os modelos: KNeighborsClassifier e SVM.
import pandas as pd
import matplotlib.pyplot as plt
from pandas.plotting import scatter_matrix
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import plot_confusion_matrix
from sklearn import metrics, svm, datasets
plt.rcParams["figure.figsize"] = (11,8)Carregando os Dados
Para que possamos iniciar nossos estudos sobre os dados, é interessante que carreguemos ele em um DataFrame Pandas, de forma que consigamos ter uma melhor visualização deles e também possamos fazer projeções com matplotlib.
URL = 'http://dadosdatascience.netlify.com/iris.csv'
names = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'class']
dataset = pd.read_csv(URL, names=names)Na variável URL reside o link que contém o arquivo CSV com os dados das flores Iris, a variável names é uma lista com o nome de cada coluna do nosso DataFrame. Através da função read_csv() do Pandas estamos carregando o arquivo CSV como uma DataFrame e guardando na variável dataset.
Sumarizando os Dados
O atributo shape nos retorna uma tupla com a dimensão dos dados
dataset.shapeOutput: (150, 5)
Com o método head() podemos visualizar os dados do topo da tabela, nesse caso vamos ver os cinco primeiros
dataset.head(5)Output:
| sepal-length | sepal-width | petal-length | petal-width | class |
|---|---|---|---|---|
| 5.1 | 3.5 | 1.4 | 0.2 | Iris-setosa |
| 4.9 | 3.0 | 1.4 | 0.2 | Iris-setosa |
| 4.7 | 3.2 | 1.3 | 0.2 | Iris-setosa |
| 4.6 | 3.1 | 1.5 | 0.2 | Iris-setosa |
| 5.0 | 3.6 | 1.4 | 0.2 | Iris-setosa |
O método describe() trará as estatísticas descritivas que incluem aquelas que resumem a tendência central, dispersão e forma da distribuição de um conjunto de dados.
dataset.describe()Output:
| sepal-length | sepal-width | petal-length | petal-width | |
|---|---|---|---|---|
| count | 150 | 150 | 150 | 150 |
| mean | 5.843 | 3.054 | 3.759 | 1.199 |
| std | 0.828 | 0.433 | 1.764 | 0.763 |
| min | 4.300 | 2.000 | 1.000 | 0.100 |
| 25% | 5.100 | 2.800 | 1.600 | 0.300 |
| 50% | 5.800 | 2.800 | 1.600 | 1.300 |
| 75% | 6.400 | 3.300 | 5.100 | 1.800 |
| max | 7.900 | 4.400 | 6.900 | 2.500 |
Podemos também utilizar o método value_counts() para obtermos o número de valores de cada classe de flores.
dataset['class'].value_counts()Nosso output será:
Iris-versicolor 50
Iris-setosa 50
Iris-virginica 50
Name: class, dtype: int64Como já era de nosso conhecimento, contamos com 50 flores de cada espécie.
Visualizando Dados
Já temos um conhecimento considerável sobre os dados, porém ainda podemos utilizar o poder da visualização de forma a maximizar a nossa intuição em relação aos dados.
Veremos especificamente dois tipos de plotagens:
- Univariada: Para compreendermos melhor cada atributo
- Multivariada: Para entendermos a relação entre os atributos
Considerando que as variáveis de input de nosso conjunto de dados são numéricas, podemos criar um box plot para cada uma delas.
dataset.plot(kind='box', subplots=True, layout=(2,2))
plt.show()Nos será apresentado
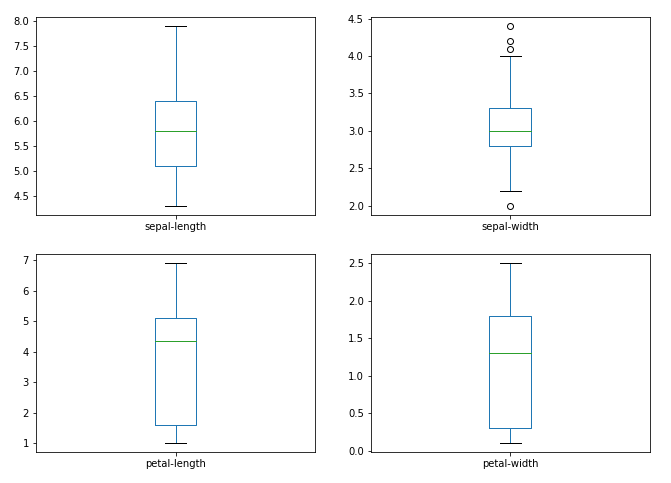
Também podemos criar um histogram para cada variável de input de forma a obtermos uma ideia a respeito da distribuição dos dados.
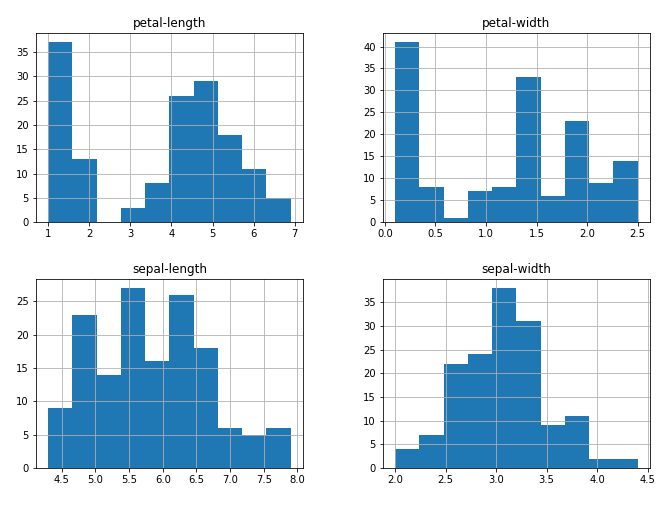
É possível observamos que duas das variáveis de input possuem uma distribuição Gaussiana.
Vamos agora olhar as interações entre as variáveis, primeiramente podemos considerar os scatterplots de todos os pares de atributos, isso pode nos ajudar a detectar relações entre as variáveis de input.
scatter_matrix(dataset)
plt.show()Ao qual vamos obter:
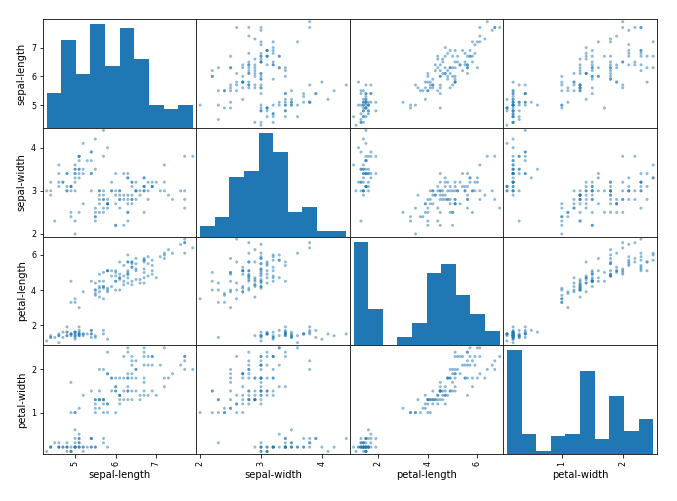
Fica evidente o agrupamento diagonal de alguns pares, nos indicando correlação e relacionamentos previsíveis.
Treinando os Algoritmos
Dividiremos nosso conjunto de dados em X, que serão as variáveis independentes que nos ajudarão na previsão e Y, que será a variável dependente, aquela que desejamos prever, nesse caso, a espécie da flor Iris.
y = f(X)
array = dataset.values
X = array[:,0:4]
y = array[:,4]Verificando o formato das novas variáveis:
print(X.shape, y.shape)Temos respectivamente: (150, 4) e (150,), ou seja, um conjunto de 2 Dimensões e um conjunto de 1 Dimensão.
Agora vamos dividir os dados em dois conjuntos: Treinamento e Teste, para esta tarefa contaremos com o auxílio da função train_test_split()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=4)Veja que optamos por manter 40% dos dados para teste, agora finalmente podemos ajustar os dados em um modelo, começaremos pelo KNeighborsClassifier.
knn = KNeighborsClassifier(n_neighbors=6)
knn.fit(X_train, y_train)Observe que escolhemos o valor 6 para hiper-parâmetro número de vizinhos, em seguida ajustamos o conjunto de treinamento no algortimo e ele nos retornará:
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=None, n_neighbors=6, p=2,
weights='uniform')Nos indicando que o modelo já foi treinado com sucesso, agora podemos utilizar o conjunto de testes para fazermos previsões e medir a acurácia de nosso algoritmo.
y_pred = knn.predict(X_test)
metrics.accuracy_score(y_test, y_pred)Ele nos retornará o valor 0.9833333333333333, indicando um excelente desempenho, tendo em vista que nosso algoritmo acertou quase 100%.
Podemos experimentar diversos valores diferentes do parâmetro n_neighbors/número de vizinhos, de forma a visualizarmos as diferentes acurácias para cada diferente valor.
k_range = range(1, 31)
scores = []
for k in k_range:
knn = KNeighborsClassifier(n_neighbors=k)
knn.fit(X_train, y_train)
y_pred = knn.predict(X_test)
scores.append(metrics.accuracy_score(y_test, y_pred))Nesse caso estamos testando 30 possibilidades, vamos agora projetar o gráfico para visualizarmos a variação de acurácia
plt.plot(k_range, scores, color="green")
plt.xlabel("K-Value")
plt.ylabel("Accuracy Score")
plt.grid()
plt.show()Imediatamente iremos obter o seguinte gráfico
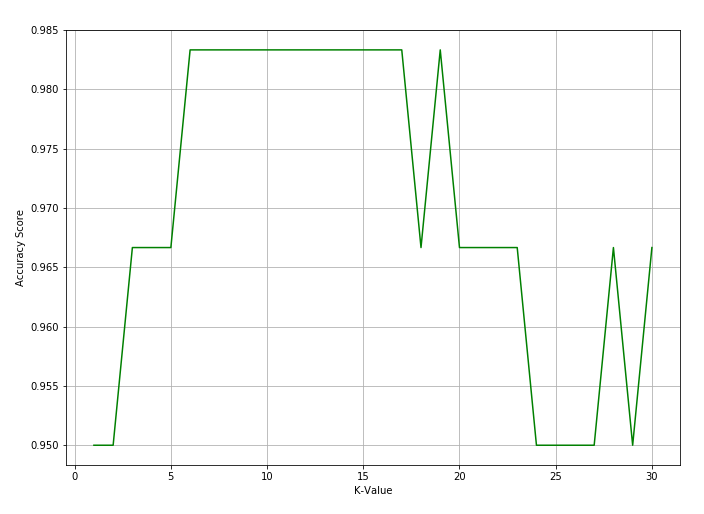
Podemos ver que os números 6…16 seriam boas opções de escolha para o valor do parâmetro, nos fornecendo uma boa acurácia.
Executando Previsões
Todos os estimadores na biblioteca Scikit-Learn possuem o método predict() que nos permite fazer previsões, podemos testar valores arbitrários por exemplo ou utilizar um conjunto separado por exemplo.
knn.predict([[4, 5, 4, 2]])Nos traz como previsão: array(['Iris-versicolor'], dtype=object)
knn.predict([[3, 2, 1, 2]])Nos traz como previsão: array(['Iris-setosa'], dtype=object)
Alterando o Modelo: Support Vector Machines (SVMs)
Scikit-Learn nos permite trocarmos de Modelo/Estimador/Algoritmo com muita facilidade
clf = svm.SVC(gamma='scale')
clf.fit(X_train, y_train)Nesse caso estamos usando o hiper-parâmetro gamma com a opção scale, novamente podemos fazer previsões e testar a acurácia.
y_prev = clf.predict(X_test)
metrics.accuracy_score(y_test, y_prev)Novamente obtivemos uma eficiência elevada: 0.9833333333333333, da mesma forma também podemos fazer novas previsões.
clf.predict([[3, 2, 1, 2]])Que nos traz: array(['Iris-setosa'], dtype=object)
Matriz de Confusão
No campo do Machine Learning e, especificamente, no problema da classificação estatística, uma matriz de confusão, também conhecida como matriz de erros, é um layout de tabela específico que permite a visualização do desempenho de um algoritmo, tipicamente um aprendizado supervisionado.
Cada linha da matriz representa as instâncias em uma classe prevista, enquanto cada coluna representa as instâncias em uma classe real (ou vice-versa). O nome deriva do fato de facilitar ver se o sistema está confundindo duas classes (ou seja, geralmente classificando incorretamente uma como outra).
Scikit-Learn nos oferece uma função plot_confusion_matrix() que nos permite projetarmos a matriz de confusão de nosso modelo.
iris = datasets.load_iris()
class_names = iris.target_names
titles_options = [("Confusion matrix, without normalization", None),
("Normalized confusion matrix", 'true')]
for title, normalize in titles_options:
disp = plot_confusion_matrix(clf, X_test, y_test,
display_labels=class_names,
cmap=plt.cm.Blues,
normalize=normalize)
disp.ax_.set_title(title)
print(title)
print(disp.confusion_matrix)
plt.show()Nos será retornado duas matrizes de confusão: Uma normalizada e outra sem normalização.
Confusion matrix, without normalization
[[25 0 0]
[ 0 16 1]
[ 0 0 18]]
Normalized confusion matrix
[[1. 0. 0. ]
[0. 0.94117647 0.05882353]
[0. 0. 1. ]]Não-Normalizada
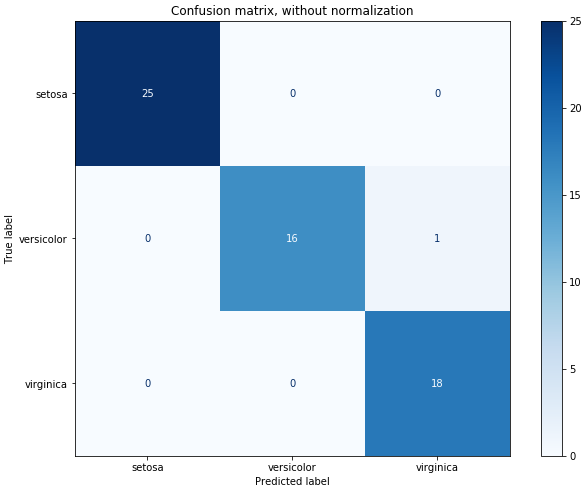
Normalizada
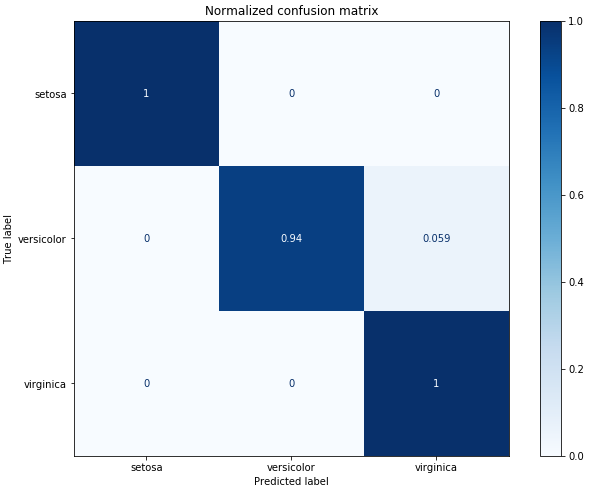
Através dela podemos visualizar que nosso modelo cometeu apenas um erro!
Conclusão
Através desse artigo e tutorial fomos capazes de aprender diversos conceitos teóricos e práticos de Machine Learning. Com esse conhecimento podemos agora nos aprofundar em temas como: Processamento de Linguagem Natural, Clusterização, Visão Computacional, Redução de Dimensionalidade e até mesmo Redes Neurais Artificiais, que são capazes de criar modelos extremamente poderosos.
Bons estudos! :)