![]()
Introdução
SQL significa Structured Query Language. SQL é usado para comunicação com um banco de dados. De acordo com ANSI(American National Standards Institute), é a linguagem padrão para sistemas de gerenciamento de banco de dados relacional.
É particularmente útil no tratamento de dados estruturados, isto é, dados que incorporam relações entre entidades e variáveis.
Originalmente baseado em álgebra relacional e cálculo relacional de tupla, o SQL consiste em muitos tipos de instruções, que podem ser informalmente classificadas como sub-linguagens, geralmente: uma linguagem de consulta de dados (DQL), uma linguagem de definição de dados (DDL), uma linguagem de controle de dados (DCL) e uma linguagem de manipulação de dados (DML).
As instruções SQL são usadas principalmente para executar tarefas como atualizar dados ou buscar dados de um banco de dados.
Alguns dos comandos SQL mais importantes são:
- SELECT - extrai dados do banco de dados
- UPDATE - atualiza dados em um banco de dados
- INSERT INTO - insere novos dados no banco de dados
- CREATE DATABASE - cria um novo banco de dados
- CREATE TABLE - cria uma nova tabela em um banco de dados
- ALTER TABLE - modifica uma tabela
- DROP TABLE - deleta uma tabela
- CREATE INDEX - cria uma índice(chave de busca)
- DROP INDEX - deleta uma índice
Eles podem ser usados para realizar quase tudo o que é necessário fazer com um banco de dados.
Breve Histórico
O SQL foi uma das primeiras linguagens comerciais a utilizar o modelo relacional de Edgar F. Codd. O modelo foi descrito em seu influente artigo de 1970, entitulado ”A Relational Model of Data for Large Shared Data Banks“.
O SQL foi desenvolvido inicialmente na IBM por Donald D. Chamberlin e Raymond F. Boyce depois de aprenderem sobre o modelo relacional de Edgar F. Codd no início dos anos 1970. Esta versão, inicialmente chamada SEQUEL (Structured English Query Language), foi projetada para manipular e recuperar dados armazenados no sistema de gerenciamento de banco de dados da IBM.
No final da década de 1970, a Relational Software, Inc. (agora Oracle Corporation) viu o potencial dos conceitos descritos por Codd, Chamberlin e Boyce e desenvolveu seu próprio RDMS baseado em SQL e com o objetivo de vendê-lo para a Marinha dos EUA, Central Intelligence Agency e outras agências governamentais dos EUA.
Em 1986, os grupos de padronização ANSI e ISO adotaram oficialmente a definição padrão da linguagem ”Database Language SQL”. Novas versões do padrão foram publicadas em 1989, 1992, 1996, 1999, 2003, 2006, 2008, 2011 e, mais recentemente, 2016.
Síntaxe
A linguagem SQL é subdividida em vários elementos da linguagem, incluindo:
- Clauses: São componentes constituintes de instruções e consultas. (Em alguns casos, estes são opcionais.)
- Expressions: No qual podem produzir valores escalares ou tabelas que consistem em colunas e linhas de dados
- Predicates: Que especificam condições que podem ser avaliadas como lógica de três valores SQL (3VL) (verdadeiro / falso / desconhecido) ou valores de verdade booleana e são usados para limitar os efeitos de instruções e consultas ou para alterar o fluxo do programa.
- Queries: Que recuperam os dados com base em critérios específicos. Este é um elemento importante do SQL.
- Statements: Que pode ter um efeito persistente nos esquemas e dados ou pode controlar transações, fluxo de programas, conexões, sessões ou diagnósticos.
As instruções SQL também incluem o terminador de instrução ponto-e-vírgula (”;”). Embora não seja obrigatório em todas as plataformas, é definido como uma parte padrão da gramática SQL.
Espaço em branco insignificante geralmente é ignorado nas instruções e consultas SQL, facilitando a formatação do código SQL para melhorar a legibilidade.
Banco de Dados Relacional
O SQL foi projetado para uma finalidade específica: consultar dados contidos em um banco de dados relacional. SQL é uma linguagem de programação declarativa baseada em conjunto, não uma linguagem de programação imperativa como C ou BASIC. No entanto, existem extensões do SQL padrão que adicionam funcionalidade de linguagem de programação procedural, como construções de controle de fluxo.
Um banco de dados relacional é um tipo de banco de dados que armazena e fornece acesso a pontos de dados relacionados entre si. Os bancos de dados relacionais são baseados no modelo relacional, uma maneira intuitiva e direta de representar dados em tabelas. Em um banco de dados relacional, cada linha da tabela é um registro com um ID exclusivo chamado chave. As colunas da tabela contêm atributos dos dados, e cada registro geralmente possui um valor para cada atributo, facilitando o estabelecimento de relacionamentos entre pontos de dados.
Sistema Gerenciador de Banco de Dados (DBMS)
Connolly e Begg definem o Sistema de Gerenciamento de Banco de Dados(DBMS) como um “sistema de software que permite aos usuários definir, criar, manter e controlar o acesso ao banco de dados”. RDBMS é uma extensão desse acrônimo que às vezes é usado quando o banco de dados subjacente é relacional. Atualmente, a maioria dos bancos de dados amplamente utilizados hoje se baseia no modelo relacional.
De acordo com a DB-Engines, em julho de 2019, os sistemas mais utilizados foram Oracle, MySQL(software livre), Microsoft SQL Server, PostgreSQL(software livre), IBM DB2, Microsoft Access, SQLite(software livre) e MariaDB (software livre).
SQLite

O SQLite é uma biblioteca em linguagem C que implementa um mecanismo de banco de dados SQL pequeno, rápido, independente, de alta confiabilidade e completo.
O SQLite é uma biblioteca em processo que implementa um mecanismo de banco de dados transacional independente, sem servidor e com configuração zero. O código para SQLite é de domínio público e, portanto, é gratuito para uso para qualquer finalidade, comercial ou privada.
SQLite é um mecanismo de banco de dados SQL incorporado. Diferentemente da maioria dos outros bancos de dados SQL, o SQLite não possui um processo de servidor separado. O SQLite lê e grava diretamente em arquivos de disco comuns. Um banco de dados SQL completo com várias tabelas, índices, triggers e visualizações está contido em um único arquivo de disco. O formato do arquivo de banco de dados é multiplataforma - você pode copiar livremente um banco de dados entre sistemas de 32 e 64 bits ou entre arquiteturas big endian e little endian.
Também é possível criar um protótipo de um aplicativo usando SQLite e depois portar o código para um banco de dados maior, como PostgreSQL ou Oracle.
O Módulo sqlite3
O módulo sqlite3 foi escrito por Gerhard Häring. Ele fornece uma interface SQL compatível com a especificação DB-API 2.0 descrita pelo PEP 249.
Para usar o módulo, você deve primeiro criar um objeto Connection que represente o banco de dados. Neste exemplo os dados serão armazenados no arquivo exemplo.db:
import sqlite3
conn = sqlite3.connect('examplo.db')Ao executarmos o script, o arquivo examplo.db (que representado o banco de dados) será criado, se eventualmente ele já existir, então nos conectaremos a ele.
Podemos também fornecer o nome especial :memory: para criar um banco de dados em memória(RAM):
import sqlite3
conn = sqlite3.connect(':memory:')Definindo uma Função de Conexão
Com todos os fundamentos em mente, criaremos então um arquivo create_con.py que será responsável por nos conectar ao banco de dados, fazendo com que possamos reaproveitá-lo em outros scripts.
import sqlite3
from sqlite3 import Error
def create_connection(db_file):
""" create a database connection to a SQLite database """
conn = None
try:
conn = sqlite3.connect(db_file)
print(sqlite3.version)
return conn
except Error as e:
print(e)
if __name__ == '__main__':
create_connection('sqlite.db')Como podemos observar, ela recebe um db_file como argumento. Através do try tentamos fazer a conexão com o banco de dados, caso esta seja sucedida, retornamos-a, caso contrário retornamos o erro ocorrido.
Criando Tabelas no Banco de Dados
Agora que temos uma função que nos permite conectar a um banco de dados, podemos finalmente definir as tabelas de nosso banco, que serão respectivamente:
books: Tabela que armazenará livros, contará com os atributos:
- id: chave primária única que identificará um livro
- title: título do livro
- author_id: id do autor do livro (chave estrangeira)
authors: Tabela que armazenerá autores, contará com os atributos:
- id: chave primária única que identificará o autor
- name: nome do autor
- born_date: data de nascimento do autor
A seguinte figura ilustra o esquema de nosso banco de dados
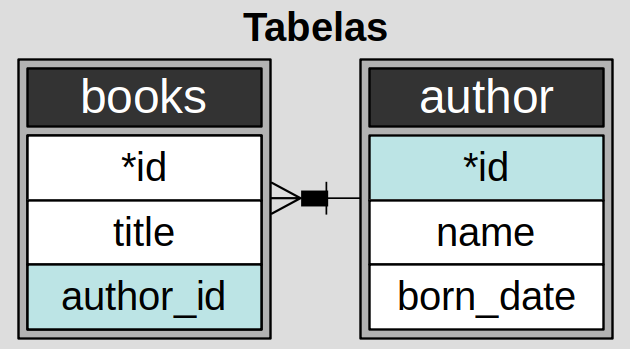
É possível observarmos que temos uma relação entre as tabelas. Especificamente uma relação One-to-many que é um tipo de cardinalidade que se refere ao relacionamento entre duas entidades (consulte também modelo entidade-relacionamento) A e B no qual um elemento de A pode estar vinculado a muitos elementos de B, mas um membro de B está vinculado a apenas um elemento de A.
Neste caso, um livro pode pertencer a apenas um autor, porém um autor pode possuir muitos livros.
Os seguintes comandos SQL são responsáveis por criar as respectivas tabelas
-- tabela author
CREATE TABLE IF NOT EXISTS authors (
id integer PRIMARY KEY,
name text NOT NULL,
born_date text
);
-- tabela books
CREATE TABLE IF NOT EXISTS books (
id integer PRIMARY KEY,
title text NOT NULL,
author_id integer NOT NULL,
FOREIGN KEY (author_id) REFERENCES authors (id)
);Vamos então incorporá-los em um script que chamarei de create_tables.py, de forma que possamos finalmente criar as tabelas.
import sqlite3
from sqlite3 import Error
from create_con import create_connection
DB = 'sqlite.db'
conn = create_connection(DB)
def create_table(conn, create_table_sql):
try:
c = conn.cursor()
c.execute(create_table_sql)
except Error as e:
print(e)
sql_create_authors_table = """
CREATE TABLE IF NOT EXISTS authors(
id integer PRIMARY KEY,
name text NOT NULL,
born_date text
);
"""
sql_create_books_table = """
CREATE TABLE IF NOT EXISTS books(
id integer PRIMARY KEY,
title text NOT NULL,
author_id integer NOT NULL,
FOREIGN KEY (author_id) REFERENCES authors (id)
);
"""
if conn is not None:
create_table(conn, sql_create_authors_table)
create_table(conn, sql_create_books_table)
else:
print('Error! Cannot create the database!')Neste script estamos importando a função create_connection() do arquivo create_con e estamos nos conectando ao banco de dados sqlite.db.
Definimos uma função create_table() que recebe como parâmetro uma conexão e um comando SQL, em seguida no bloco try criamos um objeto Cursor e com ele chamamos o método execute(), que executará o respectivo comando, se eventualmente ocorrer um erro, iremos imprimí-lo no console.
Guardamos os comandos que serão executados nas variáveis sql_create_authors_table e sql_create_books_table e chamamos a função create_table() para criar as duas tabelas.
Inserindo Dados no Banco de Dados
Para que possamos inserir dados em nosso banco de dados, contaremos com o auxílio do comando INSERT.
import sqlite3
from sqlite3 import Error
from create_con import create_connection
DB = 'sqlite.db'
conn = create_connection(DB)
cur = conn.cursor()
def create_author(conn, author):
sql = """INSERT INTO authors(name,born_date)
VALUES(?,?)"""
try:
with conn:
cur.execute(sql, author)
except sqlite3.IntegrityError:
print("couldn't add author")
return cur.lastrowid
def create_books(conn, books):
sql = """INSERT INTO books(title,author_id)
VALUES(:title,:author_id)"""
try:
with conn:
cur.executemany(sql, books)
except sqlite3.IntegrityError:
print("couldn't add books")
return cur.lastrowid
with conn:
author = ('Aldous Huxley', '1894-07-26')
author_id = create_author(conn, author)
books = [
('Brave New World', author_id),
('The Perennial Philosophy', author_id),
('The Doors of Perception', author_id),
('The Art of Seeing', author_id),
('Update Field', 5)
]
create_books(conn, books)Da mesma maneira como fizemos antes, estamos nos conectando ao banco de dados sqlite.db.
Definimos duas funções:
- create_author: Responsável por inserir um autor no banco de dados, recebe uma conexão e uma tupla que representa um autor por parâmatro.
- create_books: Responsável por inserir uma lista de livros no banco de dados, recebe como parâmetro uma conexão e uma lista de tuplas, cada uma representando um livro.
Ambas retornarão o id da uma linha inserida.
Estamos também utilizando a palavra-chave with: Os objetos de conexão podem ser usados como gerenciadores de contexto que confirmam ou revertem automaticamente as transações. No caso de uma exceção, a transação é revertida; caso contrário, a transação será confirmada.
Finalmente criamos um autor e inserimos ele no banco de dados com a função create_author(), em seguida criamos uma lista de livros os inserimos com a função create_books().
Atualizando Dados do Banco de Dados
Utilizaremos o comando SQL UPDATE para atualizar nossos dados.
import sqlite3
from sqlite3 import Error
from create_con import create_connection
DB = 'sqlite.db'
conn = create_connection(DB)
def update_book(conn, book):
sql = """UPDATE books SET
title = ?,
author_id = ?
WHERE id = ?"""
cur = conn.cursor()
cur.execute(sql, book)
conn.commit()
book = ('Ape and Essence', 1, 5)
with conn:
update_book(conn,book)Depois de nos conectarmos ao banco de dados, definimos uma função update_book() que recebeŕá como parâmetro uma conexão e um livro a ser atualizado, em seguida definimos uma tupla que representará um livro a ser atualizado, nesse caso estamos fornecendo o título do livro, o novo id do autor e o id do livro, finalmente atualizamos o banco de dados com a função update_book().
Selecionando Dados do Banco de Dados
A instrução SELECT recupera zero ou mais linhas de uma ou mais tabelas de banco de dados. Na maioria dos aplicativos, o SELECT é o comando da linguagem de manipulação de dados mais comumente usado.
import sqlite3
from sqlite3 import Error
from create_con import create_connection
DB = 'sqlite.db'
conn = create_connection(DB)
cur = conn.cursor()
def select_book(conn, id):
cur.execute('SELECT * from books WHERE id=:id', {'id':id})
row = cur.fetchone()
print(row)
def select_books(conn):
cur.execute('SELECT * from books')
rows = cur.fetchall()
for row in rows:
print(row)
def select_author(conn, id):
cur.execute('SELECT * from authors WHERE id=?', (id,))
row = cur.fetchone()
print(row)
def select_authors(conn):
cur.execute('SELECT * from authors')
rows = cur.fetchall()
for row in rows:
print(row)
with conn:
print('SELECT * from books;')
select_books(conn)
print('SELECT * from authors;')
select_authors(conn)
print('SELECT * from books where id = 3;')
select_book(conn, 3)
print('SELECT * from authors where id = 1;')
select_author(conn, 1)Após nos conectarmos ao banco de dados, definimos 4 funções que serão responsáveis por selecionar dados em nossas tabelas:
- select_book(): recebe uma conexão e um id como parâmetro e executa o comando SELECT de forma a selecionar um livro com o id específico
- select_books(): recebe uma conexão como parâmetro e executa o comando SELECT de forma a selecionar todos os livros da tabela
- select_author(): recebe uma conexão e um id como parâmetro e executa o comando SELECT de forma a selecionar um autor com id específico
- select_authors(): recebe uma conexão como parâmetro e executa o comando SELECT de forma a selecionar todos os autores da tabela
Finalmente, com nosso gerenciador de contexto with, executamos nossas funções que nos retornarão os dados selecionados.
Deletando Dados do Banco de Dados
A instrução SQL DELETE remove um ou mais registros de uma tabela.
import sqlite3
from sqlite3 import Error
from create_con import create_connection
DB = 'sqlite.db'
conn = create_connection(DB)
def delete_book(conn, id):
sql = f'DELETE FROM books where id = {id}'
cur = conn.cursor()
cur.execute(sql)
conn.commit()
def delete_all_authors(conn):
sql = 'DELETE FROM authors'
cur = conn.cursor()
cur.execute(sql)
conn.commit()
with conn:
delete_book(conn, 5)
delete_all_authors(conn)Logo depois de nos conectarmos com o banco de dados, definimos duas funções:
- delete_book(): no qual recebe uma conexão e um id como parâmetro e deleta o livro com o id especificado.
- delete_all_authors(): que recebe uma conexão como parâmetro e deleta todos os autores do banco de dados.
Por fim, com muito cuidado, sabendo que perderemos os dados, executamos ambas as funções.
Usando Métodos de Atalho
Usando os métodos não padronizados execute(), executemany() e executescript() do objeto Connection, seu código pode ser escrito de forma mais concisa, porque você não precisa criar explicitamente os objetos Cursores. Em vez disso, os objetos Cursor são criados implicitamente e esses métodos de atalho retornam os objetos do cursor. Dessa forma, você pode executar uma instrução SELECT e iterá-la diretamente usando apenas uma única chamada no objeto Connection.
Vejamos um exemplo
import sqlite3
pokemons = [
("Bulbasaur", "Grass"),
("Charmander", "Fire"),
("Squirtle", "Water"),
("Pikachu", "Electric")
]
con = sqlite3.connect(":memory:")
con.execute("create table pokemon(name, type)")
con.executemany("insert into pokemon(name, type) values (?, ?)", pokemons)
for row in con.execute("select name, type from pokemon"):
print(row)
con.close()Dessa forma, não há necessidade de estabelecermos um objeto cursor, executamos os comandos SQL diretamente com o objeto Conexão. Nesse caso estamos nos conectando a um banco de dados que residirá apenas em memória, criando uma tabela pokemon e inserindo uma lista de pokemons em nosso banco de dados, finalmente fazemos a seleção dos dados e os apresentamos no console.
Definindo uma Shell para Execução de Comandos
O seguinte script que chamamos de shell.py define uma Shell que nos permite executarmos comandos SQL em um banco de dados, neste caso estamos nos conectando com o banco de dados sqlite.db, onde residem as tabelas books e authors.
import sqlite3
con = sqlite3.connect("sqlite.db")
con.isolation_level = None
cur = con.cursor()
buffer = ""
print("Enter your SQL commands to execute in sqlite3.")
print("Enter a blank line to exit.")
while True:
line = input()
if line == "":
break
buffer += line
if sqlite3.complete_statement(buffer):
try:
buffer = buffer.strip()
cur.execute(buffer)
if buffer.lstrip().upper().startswith("SELECT"):
print(cur.fetchall())
except sqlite3.Error as e:
print("An error occurred:", e.args[0])
buffer = ""
con.close()O método complete_statement() retorna True se a string sql contiver uma ou mais instruções SQL completas terminadas por ponto e vírgula. Ele não verifica se o SQL está sintaticamente correto, apenas que não há literais de cadeia de caracteres não fechados e a instrução é encerrada por ponto e vírgula.
Executamos o script com o comando python shell.py e agora podemos executar comandos SQL diretamente, por exemplo:
Selecionando todos os autores
SELECT * from authors;Selecionando todos os livros
SELECT * from books;Selecionando o livro com id=1
SELECT * from books WHERE id = 1;Selecionando os livros que começam com The D
SELECT * from books WHERE title LIKE 'The D%';Selecionando os livros ordenados pelo título
SELECT * FROM books ORDER BY title;Ao pressionarmos a tecla enter podemos imediamente sair da shell.
Caso possua alguma dúvida em relação ao código apresentado neste tutorial, você pode acessar os arquivos respectivos no repositório: SQL.
Conclusão
Através de nosso estudo, conseguimos descobrir que existe uma vastidão de conteúdo e literatura sobre os bancos de dados, uma vez que eles são um conceito de extrema importância na computação. O SQL nos permite armazenar, consultar e manipular dados e é amplamente usado na indústria de software devido ao seu poder.
Neste pequeno tutorial fomos capazes de aprender conceitos importantes relacionados aos bancos de dados, bem como executar experimentos com o SQLite através de uma interface Python que nos permitiu executar diversos comandos SQL de maneira programática.