
Introdução
O Web Browser, também conhecido como Navegador da Web, é um software para acessar informações na World Wide Web. Quando um usuário solicita um site específico, o Web Browser recupera o conteúdo necessário de um servidor da Web e exibe a página da Web resultante no dispositivo do usuário.
Os navegadores da Web são usados em vários dispositivos, incluindo desktops, laptops, tablets e smartphones. Em 2019, cerca de 4,3 bilhões de pessoas usavam um navegador, e este número cresce cada vez mais. Atualmente o navegador mais usado é o Google Chrome.
Ao acessarmos um website com um determinado navegador, é possível que tenhamos interações com esse site. Por exemplo:
- Podemos clicar em hyperlinks e botões
- Podemos preencher formulários com textos e enviar os dados para um servidor da Web
- Podemos deslizar a scrolling bar, também conhecida como barra de rolagem
Todas essas interações citadas podem ser automatizadas com ferramentas especializadas.
Automação do Web Browser
A automação do Web Browser é um processo em que determinadas etapas no Web Browser são executadas repetidamente para garantir a operação correta da funcionalidade da aplicação web.
Pode ser aplicado para testes de controle de qualidade no processo de desenvolvimento e para controle da acessibilidade e desempenho do sistema de informações durante a implementação.
Existem muitas ferramentas de automação de navegador Web. Para este guia escolhi o framework Selenium, devido a sua natureza open-source e eficiência comprovada, bem como um grande volume de materiais disponível na Internet.
Selenium
O Selenium WebDriver dirige/pilota um Web Browser nativamente, como um usuário real faria, localmente ou em máquinas remotas.
O Selenium é um projeto abrangente que engloba uma variedade de ferramentas e bibliotecas, permitindo a automação do navegador da web. O Selenium fornece especificamente infraestrutura para a especificação W3C WebDriver.
Selenium atualmente fornece APIs de cliente para linguagens como Java, C#, Ruby, JavaScript, R e Python. Neste guia vamos utilizar a API Selenium-Python.
Selenium-Python
As ligações do Selenium-Python fornecem uma API simples para gravar testes funcionais/de aceitação usando o Selenium WebDriver. Através da API Selenium Python, podemos acessar todas as funcionalidades do Selenium WebDriver de maneira intuitiva com Python.
As ligações do Selenium Python fornecem uma API conveniente para acessar os Selenium WebDrivers como Firefox, Internet Explorer, Google Chrome, etc. As versões atuais suportadas do Python são 2.7, 3.5 e superior.
Instalação
A melhor maneira de instalarmos Selenium-Python, de acordo com a documentação, é através do gerenciador de pacotes pip. Para isso, precisamos então executar o seguinte comando:
pip install seleniumDica: você pode também considerar usar um virtualenv para criar ambientes Python isolados.
Drivers
O Selenium requer um driver para interagir com o navegador escolhido. O Firefox, por exemplo, requer o geckodriver.
Para este guia, vamos utilizar o Google Chrome, porém sinta-se livre para escolher o seu navegador favorito.
A tabela a seguir mostra a relações dos Web Browsers mais populares e os seus respectivos drivers
| Navegador | Driver |
|---|---|
| Chrome | ChromeDriver |
| Edge | Edge Web Driver |
| Firefox | GeckoDriver |
| Safari | Safari Web Driver |
Faça o download do driver respectivo ao seu Web Browser e Sistema Operacional, extraia o arquivo e copie para a localização /usr/bin ou /usr/local/bin.
Caso você esteja utilizando uma máquina Windows, você pode consultar a documentação para mais detalhes.
Agora que já temos os conhecimentos fundamentais e instalamos todas as ferramentas necessárias, finalmente podemos iniciar nosso guia.
Primeiros Passos
Iniciaremos criando o arquivo Python de nosso projeto, que eu irei chamar de main.py
touch main.pyImportaremos o webdriver da biblioteca selenium e vamos definir uma classe chamada GoogleBot, que será o nosso robô experimental, imediatamente vamos implementar um construtor __init__ que irá inicializar o Web Browser ao criarmos uma instância dessa classe.
from selenium import webdriver
class GoogleBot():
def __init__(self):
self.driver = webdriver.Chrome()Definido este código, vamos executá-lo no modo interativo: python -i main.py, uma vez que estamos no modo interativo, podemos enviar comandos para interagir com esse script, vamos então criar uma instância da classe GoogleBot:
>>> bot = GoogleBot()Observe que será aberta uma janela do navegador, podemos agora começar a incrementar nossa classe com métodos que nos permitirão interagir com as páginas web.
Criando Interações
Primeiramente vamos definir um método que irei chamar de start(), ele será responsável por abrir a página https://www.google.com/.
from selenium import webdriver
class GoogleBot():
def __init__(self):
self.driver = webdriver.Chrome()
def start(self):
self.driver.get('https://www.google.com')Executando novamente o script no modo interativo e instanciando o Robô, é possível agora invocarmos o método start():
>>> bot.start()Será aberta a página inicial do mecanismo de busca Google.com, nosso objetivo agora é definir um método capaz de inserir textos no formulário de pesquisas do Google, sendo assim, vamos incrementar a nossa classe GoogleBot
from selenium import webdriver
class GoogleBot():
def __init__(self):
self.driver = webdriver.Chrome()
def start(self):
self.driver.get('https://www.google.com')
def enter_text(self, text):
search_field = self.driver.find_element_by_xpath('//*[@id="tsf"]/div[2]/div[1]/div[1]/div/div[2]/input')
search_field.send_keys(text)Observe que definimos um método chamado de enter_text, este que recebe como parâmetro um text, que será o texto a ser pesquisado.
Perceba também que estamos utilizando o método find_element_by_xpath() da biblioteca selenium, e estamos passando para ele como argumento o XPath referente ao elemento HTML do formulário.
A maioria dos navegadores modernos oferecem uma ferramenta para Desenvolvimento Web embutida e é através delas que podemos selecionar elementos de uma página web de diversas maneiras, nesse caso específico optamos por utilizar o XPath.
No Google Chrome, por exemplo, podemos clicar com o botão direito no elemento e escolher a opção Inspecionar:
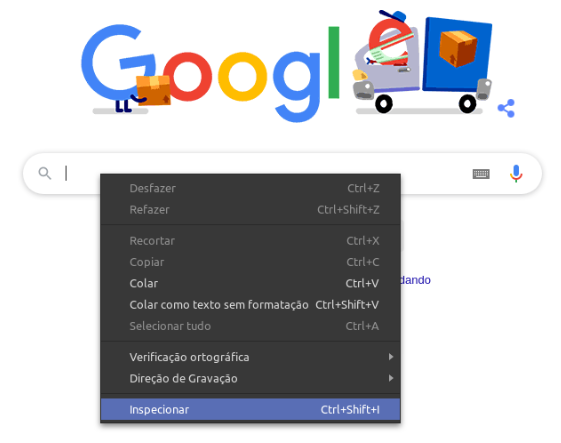
Ao abrir o código-fonte HTML da página, selecionamos o elemento desejado e copiamos o XPath:
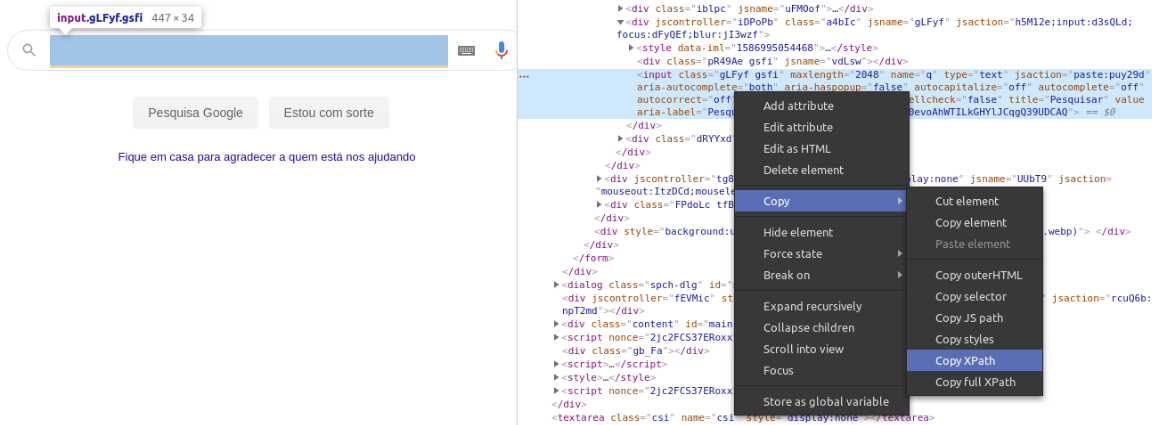
Com o elemento selecionado e armazenado na variável search_field, executamos o método send_keys() e passamos a ele como argumento o texto que desejamos usar no preenchimento do formulário.
Podemos agora testar o método enter_text em nosso Python interativo
>>> bot.enter_text('Guia de Programação Python')Veja que o formulário de pesquisas será preenchido com o texto que passamos como parâmetro. Antes de clicarmos no botão pesquisar, acredito que seja importante definirmos um método que irá limpar o campo do formulário de pesquisa:
from selenium import webdriver
class GoogleBot():
def __init__(self):
self.driver = webdriver.Chrome()
def start(self):
self.driver.get('https://www.google.com')
def enter_text(self, text):
search_field = self.driver.find_element_by_xpath('//*[@id="tsf"]/div[2]/div[1]/div[1]/div/div[2]/input')
search_field.send_keys(text)
def clear_text(self):
search_field = self.driver.find_element_by_xpath('//*[@id="tsf"]/div[2]/div[1]/div[1]/div/div[2]/input').clear()Como podemos perceber, o método chamado de clear_text() é muito simples, estamos apenas selecionando o mesmo formulário e executando o método clear(), que irá limpar o campo do formulário de pesquisa, para ver se tudo correu bem, podemos testá-lo:
>>> bot.clear_text()Agora que já somos capazes de inserir textos no formulário, e limpá-lo caso seja necessário, podemos agora definir um método que irá clicar no botão Pesquisa Google, irei chamá-lo de search():
from selenium import webdriver
class GoogleBot():
def __init__(self):
self.driver = webdriver.Chrome()
def start(self):
self.driver.get('https://www.google.com')
def enter_text(self, text):
search_field = self.driver.find_element_by_xpath('//*[@id="tsf"]/div[2]/div[1]/div[1]/div/div[2]/input')
search_field.send_keys(text)
def clear_text(self):
search_field = self.driver.find_element_by_xpath('//*[@id="tsf"]/div[2]/div[1]/div[1]/div/div[2]/input').clear()
def search(self):
search_btn = self.driver.find_element_by_xpath('//*[@id="tsf"]/div[2]/div[1]/div[2]/div[2]/div[2]/center/input[1]')
search_btn.click()Dessa vez estamos selecionando o elemento botão com o texto “Pesquisa Google” e guardando na variável search_btn e depois executamos o método click() que nos levará à lista de resultados da pesquisa.
Podemos agora testar nosso novo método
>>> bot.start()Será aberta uma página de resultados referente ao texto que pesquisamos.
Até então estamos caminhando bem, acredito que agora será interessante definirmos um método que irá capturar todos os links da página que estamos, vamos chamá-lo de get_links():
from selenium import webdriver
class GoogleBot():
def __init__(self):
self.driver = webdriver.Chrome()
def start(self):
self.driver.get('https://www.google.com')
def enter_text(self, text):
search_field = self.driver.find_element_by_xpath('//*[@id="tsf"]/div[2]/div[1]/div[1]/div/div[2]/input')
search_field.send_keys(text)
def clear_text(self):
search_field = self.driver.find_element_by_xpath('//*[@id="tsf"]/div[2]/div[1]/div[1]/div/div[2]/input').clear()
def search(self):
search_btn = self.driver.find_element_by_xpath('//*[@id="tsf"]/div[2]/div[1]/div[2]/div[2]/div[2]/center/input[1]')
search_btn.click()
def get_links(self):
links = self.driver.find_elements_by_xpath('//*[@id="rso"]/div/div/div/a')
for link in links:
print(link.get_attribute('href'))Selecionamos um elemento <a> através do XPath, com o for loop percorremos todos os links e apresentamos em nosso console apenas o texto do atributo href. Importante notar que estamos utilizando nesse caso o método find_elements_by_xpath() no plural, indicando que desejamos pegar todos os links!
Testando nosso novo método
>>> bot.get_links()Ele irá nos retornar todos os links da página de resultados atual.
Para finalizar o nosso robô experimental, vamos definir mais dois métodos:
save_links(): Será responsável por salvar os links de nossa página atual em um arquivo de nome escolhido por nóschange_page()Será responsável por trocar a página de resultados da pesquisa, de forma que possamos navegar pelas diversas páginas
O código complete ficará da seguinte forma
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
class GoogleBot():
def __init__(self):
self.driver = webdriver.Chrome()
def start(self):
self.driver.get('https://www.google.com')
def enter_text(self, text):
search_field = self.driver.find_element_by_xpath('//*[@id="tsf"]/div[2]/div[1]/div[1]/div/div[2]/input')
search_field.send_keys(text)
def clear_text(self):
search_field = self.driver.find_element_by_xpath('//*[@id="tsf"]/div[2]/div[1]/div[1]/div/div[2]/input').clear()
def search(self):
search_btn = self.driver.find_element_by_xpath('//*[@id="tsf"]/div[2]/div[1]/div[2]/div[2]/div[2]/center/input[1]')
search_btn.click()
def get_links(self):
links = self.driver.find_elements_by_xpath('//*[@id="rso"]/div/div/div/a')
for link in links:
print(link.get_attribute('href'))
def save_links(self, filename):
links = self.driver.find_elements_by_xpath('//*[@id="rso"]/div/div/div/a')
with open(filename, 'w') as f:
for link in links:
f.write(link.get_attribute('href') + '\n')
def change_page(self, page_num):
try:
page_btn = self.driver.find_element_by_xpath(f"//a[@aria-label='Page {page_num}']")
page_btn.click()
except NoSuchElementException:
print('Element out of range')Note que método save_links() recebe um filename como argumento, que é o nome do arquivo que iremos salvar os links, imediatamente estamos selecionando os links como já tinhamos feito antes, abrindo o arquivo respectivo e escrevendo todos os links nele.
Já o método change_page() recebe um page_num como argumento, que é o número da página que desejamos navegar. Estamos utilizando um bloco try: e except para tratar a exceção de uma situação em que venhamos a selecionar um elemento que não existe, por este motivo importamos o NoSuchElementException no topo de nosso arquivo.
Podemos agora finalmente experimentar o Robô
>>> bot = GoogleBot()
>>> bot.start()
>>> bot.enter_text('Guia de Programação Python')
>>> bot.search()
>>> bot.get_links()
>>> bot.save_links('links.txt')
>>> bot.change_page(5)Ao navegarmos até uma página que o elemento esteja fora de alcance, teremos a exceção tratada:
>>> bot.change_page(12)
# Element out of rangeCom essa base é possível criarmos robôs para interagir com qualquer aplicação, sinta-se livre para aperfeiçoá-lo e automatizá-lo da forma que melhor lhe agradar.
Conclusão
Com esse guia fomos capazes de aprender sobre Web Browsers e a capacidade que temos de automatizar as tarefas de interação com os mesmos, tornando assim possível a criação de robôs e ferramentas de testes.
Para isso contamos com o auxílio da linguagem Python e o framework Selenium. Você pode checar as referências para mais detalhes específicos, como por exemplo, deslizar a barra de rolagem ou até mesmo executar um script Javascript.
Bons estudos!